Analýza obsahu výpovědí respondentov
Spoločnosť SC&C realizovala v roku 2018 online výskum k 100. výročiu vzniku Československej republiky. Jednou z otázok bola aj otvorená otázka Čo by ste popriali štátu k narodeninám?. Analyzovať obsah výpovedí takýchto otvorených otázok je náročné najmä z časového hľadiska, kedy bežne človek musí tieto odpovede prečítať a následne kategorizovať do niekoľkých málo skupín, s ktorými bude ďalej pracovať. V súčasnosti už existujú nástroje, ktoré umožňujú analýzu obsahu automatizovať a to tak, že z výpovedí respondentov extrahujú heslá charakterizujúce obsah výpovedí respondentov. Na základe týchto hesiel je možné následne rozdeliť respondentov do určitého počtu klastrov podľa podobnosti výpovedí. Toto bude aj našou úlohou pre otvorenú otázku Čo by ste popriali štátu k narodeninám?.
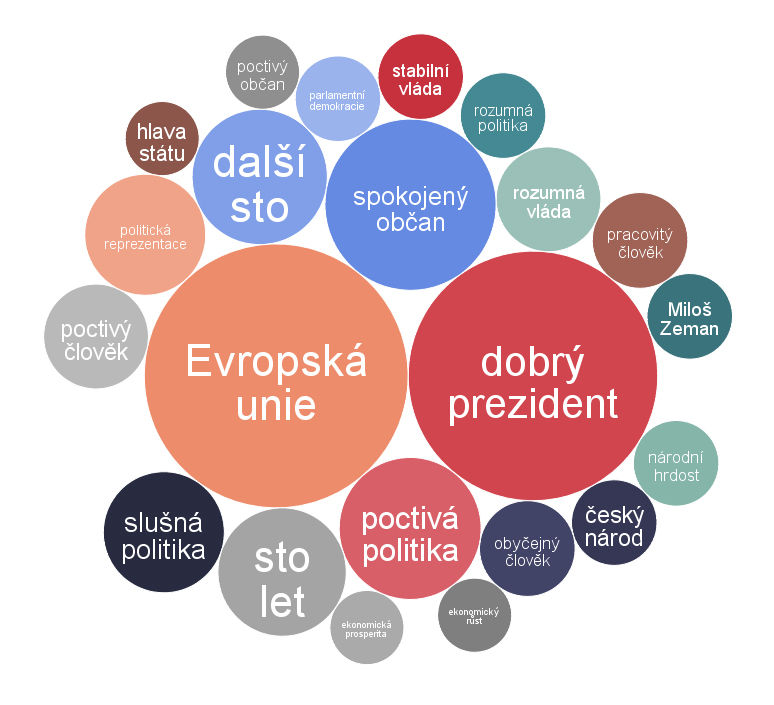
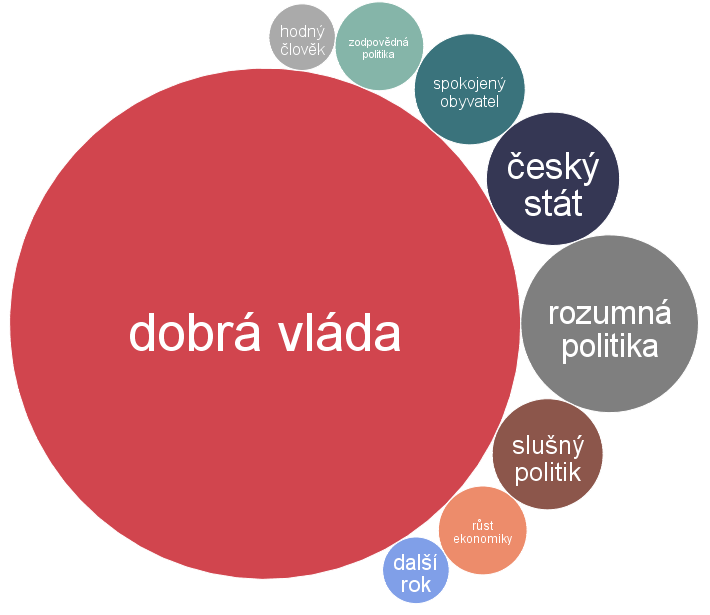
Prvých sto najpočetnejších extrahovaných dvojslovných hesiel sme zobrazili pomocou bublinového grafu (Obrázok 1). Čím väčšia bublina, tým väčšie zastúpenie daného hesla. Heslá, ktoré sa často opakovali vo výpovediach a dá sa z nich vydedukovať čo by popriali štátu k narodeninám sú dobrá politika, dobrá vláda, rozumná politika, poctivá politika, slušná politika, rozumná vláda, dobrý prezident, jiný prezident, jiný premiér, nová vláda, selský rozum, zdravý rozum, právní stát, spokojený občan atď.
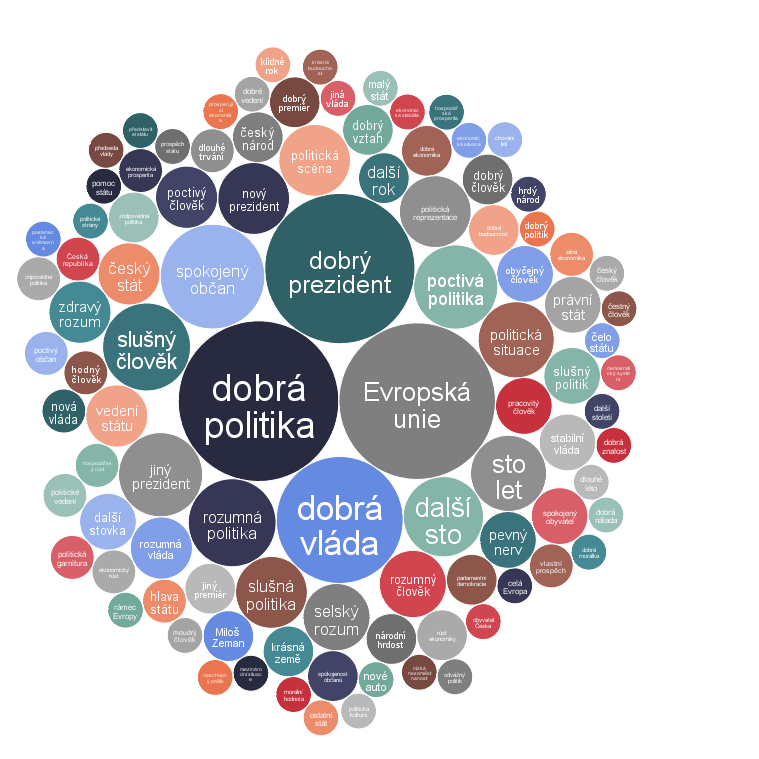
Súčasťou analýzy obsahu môže byť aj priradenie typu extrahovaného hesla. Napríklad typ pomenovaná entita (ENTITIES). Extrahované entity sme si teraz pre zmenu zobrazili pomocou oblaku slov (word cloud, Obrázok 2). Čím väčší text, tým väčšie zastúpenie danej entity vo výpovediach. Väčšinou sa jedná o mená osôb z politiky ako je napríklad Babiš, Zeman, Fiala, Okamura, Klaus, Masaryk, Kalousek, Kiska, Havel atď. alebo názvy politických strán ako je napríklad KSČM, ODS, ČSSD, TOP 09, KDU-ČSL atď. Medzi entitami sa vo výpovediach najčastejšie vyskytovala Evropská unie.

Rozdelením respondentov do štyroch klastrov podľa podobností výpovedí (extrahovaných dvojslovných hesiel) a následným zobrazením extrahovaných dvojslovných hesiel pomocou bublinových grafov pre jednotlivé klastre zistíme, že respondenti v prvom klastri si prevažne želajú lepšieho prezidenta (Obrázok 3), v druhom klastri lepších politikov (Obrázok 4) a v treťom klastri lepšiu vládu (Obrázok 5). Heslá v grafoch sú v základnom tvare a vhodné bolo sa pozrieť priamo na výpovede respondentov najmä pre druhý klaster. V štvrtom klastri sú respondenti, ktorých extrahované heslá z výpovedí boli maximálne jednoslovné.
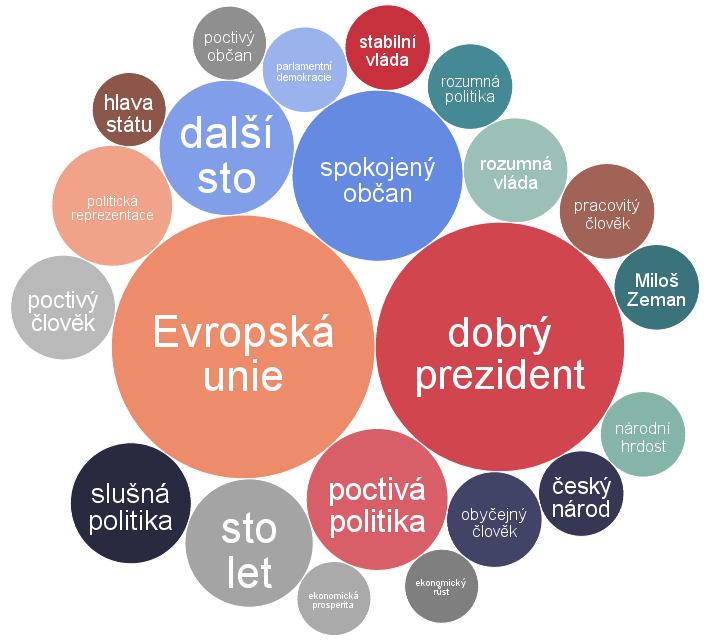
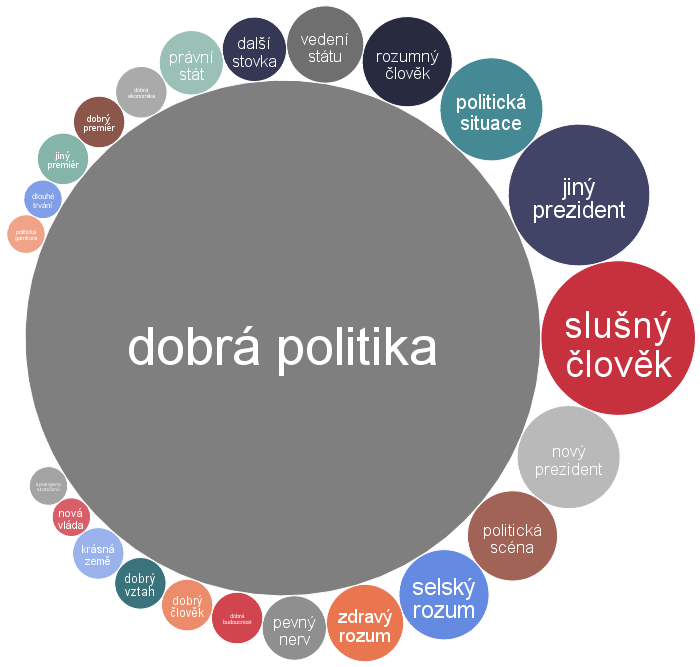
Záverom tejto analýzy môžeme povedať, že sa nám podarilo pomerne úspešne a jednoducho rozdeliť výpovede do štyroch klastrov a zistiť aké heslá v nich prevažujú. Ďalej by sa s klastrami dalo pracovať a analyzovať ich vo vzťahu k ďalším premenným dostupných z výskumu. Napríklad vo vzťahu k pohlaviu, veku, vzdelaniu, regiónu atď.
Analýza obsahu v IBM SPSS Statistics
Všetky prezentované výstupy a závery pochádzajú zo softvéru PS_Imago_PRO, ktorého súčasťou je IBM SPSS Statistics. Aby ste však mohli realizovať analýzu obsahu potrebujete si zakúpiť samostatný modul Acrea Text Analytics s procedúrou Labels. Tá sa jednoducho nainštaluje do softvéru IBM SPSS Statistics a pod menu Custom pribudne nová procedúra ACREA TA Labels (Obrázok 6).
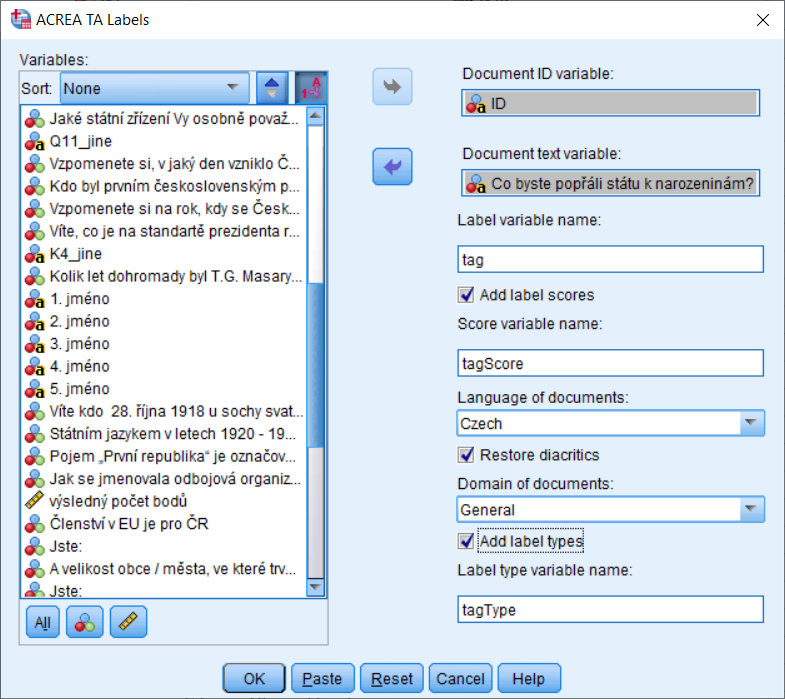
Zadávanie je štandardné ako ste zvyknutý z iných procedúr. Procedúra ACREA TA Labels extrahuje z textového dokumentu heslá charakterizujúce obsah dokumentu do novej dátovej matice, kde riadky reprezentujú jednotlivé nájdené heslá. Jeden dokument je reprezentovaný viacerými riadkami s rovnakým identifikátorom dokumentu. Voliteľne ide ku každému heslu priradiť číselné skóre alebo typ hesla. Pred samotnou extrakciou hesiel ide realizovať automatické rozpoznanie jazyka a pre český jazyk aj nahradenie diakritiky pokiaľ chýba. Extrahované heslá ovplyvňuje výber domény, odkiaľ dokumenty pochádzajú. Primárne je procedúra určená na analýzu českého prípadne slovenského textu avšak umožňuje aktuálne analyzovať aj texty z iných jazykov ako je angličtina a nemčina. Súčasťou je aj dokumentácia pod tlačidlom Help, ktorá sa zobrazí vo webovom prehliadači a je z nej zrejmé čo jednotlivé políčka a nastavenia procedúry znamenajú (Obrázok 7).
Procedúra má tiež aj svoju vlastnú syntax ACREA TA LABELS (Obrázok 8) a je tak možné ju využiť pri automatizácii procesov na pravidelnej báze.

Potřebujete poradit, jak využívat vaše data? Chcete zefektivnit a urychlit vaši práci?
Využijte naši bezplatnou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení i pro váš projekt nebo se přihlaste na náš nový kurz Text mining, kde vás naučíme tradiční dataminingové postupy, jak extrahovat a využít užitečné informace ze svých elektronických dat. Udělejte si pořádek na jedno kliknutí ve všech svých textových dokumentech, jako jsou například emaily, novinové články, vědecké publikace, zápisky z call center, korespondence na sociálních sítích nebo jen komentáře k produktům nabízející také množství skrytých informacích.

