ACREA TEXT ANALYTICS
- modul IBM SPSS Statistics pro analýzu textu
Díky modulu ACREA Text Analytics můžete analyzovat sentiment dokumentu či extrahovat klíčová slova přímo ve statistickém softwaru IBM SPSS Statistics. Modul je tvořen souborem procedur umožňujících transformovat nestrukturovaná textová data z dokumentů psaných v přirozeném jazyce do strukturované (tabulkové) podoby vhodné pro další strojové zpracování.
Online ukázka softwaru zdarma
Jedna online schůzka vám ušetří hodiny času i hledání informací

Dozvíte se:
- jak software funguje v praxi
- jak rozšíří analýzu dat v IBM SPSS Statistics
- s jakými úlohami analýzy textu se často setkáváme
... a to vše nezávazně a přehledně
Analýza sentimentu
Modul podporuje strojovou, jazykově závislou extrakci atributů ze všech významných světových jazyků a i z českých a slovenských textů a klasifikaci dokumentů podle jejich sentimentu. Určení sentimentu textového dokumentu je jednou z klasifikačních úloh, kdy dokumenty rozřazujeme do kategorií pozitivního a negativního sentimentu.
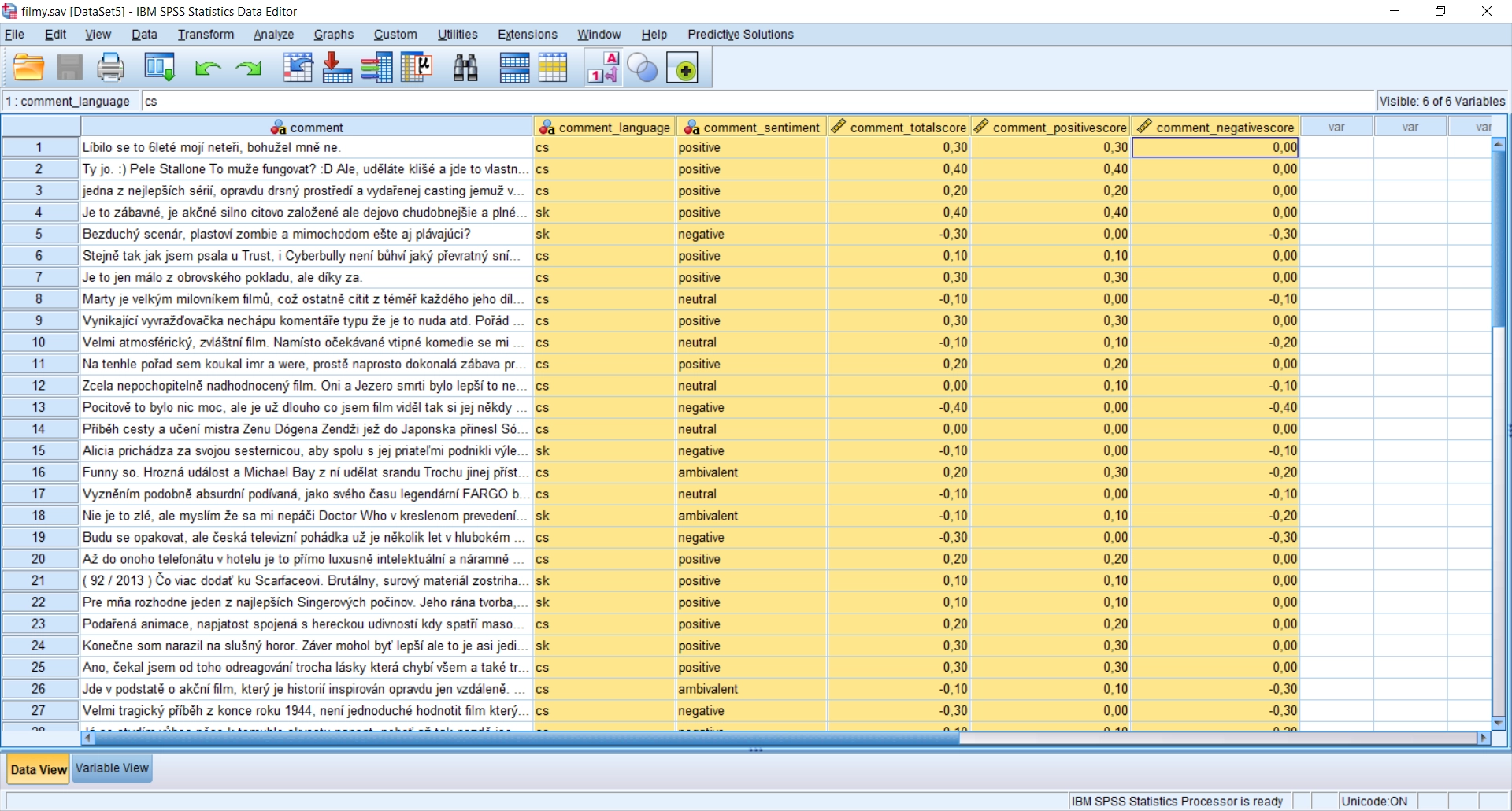
Číselné skóre úměrné pozitivnímu či negativnímu vyznění dokumentu umožní dokumenty řadit a soustředit se pouze na ty nejvíce emotivní.
Kromě celkového skóre jsou k dispozici i samostatná skóre pro pozitivní a negativní sentiment. Můžete tak identifikovat ambivalentní dokumenty, které obsahují jak pozitivní, tak i negativní vyznění.
Modul odliší i dokumenty bez sentimentu a vyhodnotí jako neutrální.
Extrakce termínů
Volný text zapsaný v přirozeném jazyce ukrývá velké množství informací. Aby tyto informace mohly být vytěženy pomocí běžného strojového učení, je třeba dokumenty popsat sadou strukturovaných atributů.
Z každého dokumentu jsou extrahovány hesla vypovídající o jeho obsahu. Hesla je možné využít jako strukturovanou reprezentaci textových dokumentů v úlohách na zpracování samotných dokumentů, jako jsou klasifikace či klastrování dokumentů.
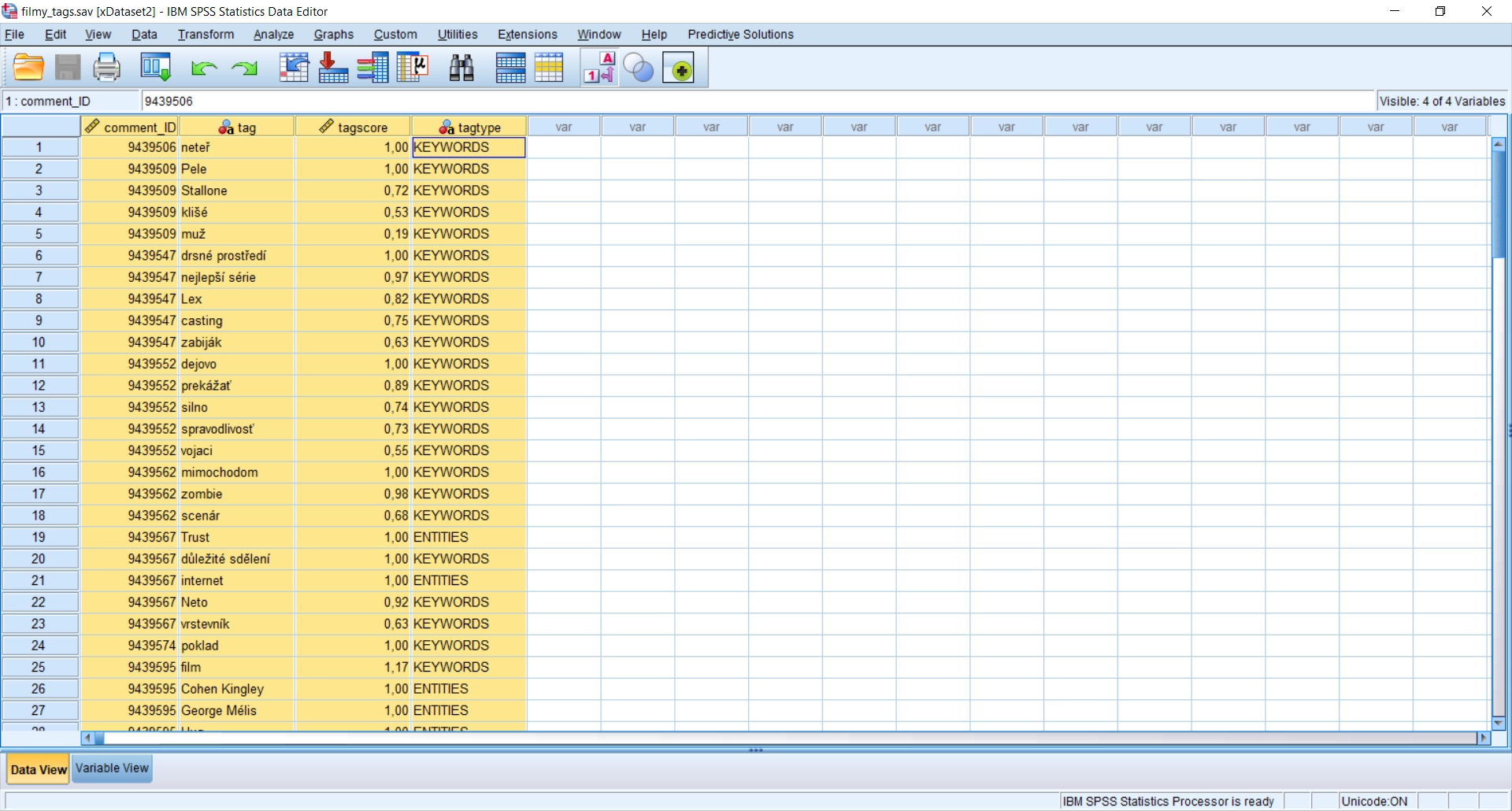
Extrahovaná hesla zahrnují klíčová slova uvedená v základním tvaru. Obsahují jak jednoslovné termíny, tak sousloví.
Díky specifickým lingvistickým zdrojům se nemusí jednat o přesné termíny z textu, ale do jednoho hesla mohou být shrnuta synonyma nebo například heslo může vyjadřovat plné znění zkratky vyskytující se v textu.
Kromě klíčových slov v heslech najdeme jména osob, firem či míst.
Extrakce pojmenovaných entit
Modul umožňuje pokročilou extrakci pojmenovaných entit z textových dokumentů v různých světových jazycích, včetně češtiny a slovenštiny, a jejich klasifikaci na základě typu entity.
Identifikace pojmenovaných entit je klíčovým krokem v analýze textu, kdy jsou jednotlivé části textu rozpoznány a přiřazeny k předdefinovaným kategoriím jako jsou osoby, organizace nebo místa.
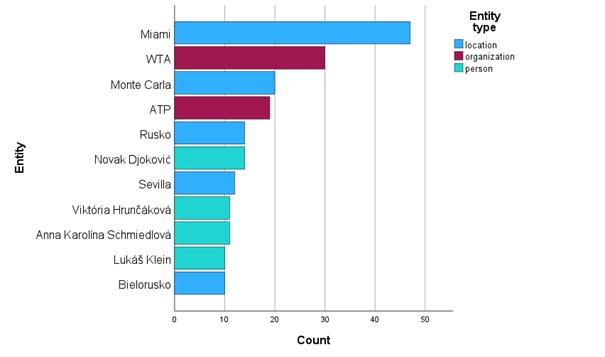
Modul poskytuje možnost detailní analýzy entit, což zahrnuje nejen jejich rozpoznání a klasifikaci, ale také určení jejich sentimentu. To znamená, že každá extrahovaná entita může být ohodnocena z hlediska sentimentu, který může být pozitivní, negativní, neutrální, velmi pozitivní, velmi negativní nebo ambivalentní.
Pro každou entitu lze stanovit celkové skóre sentimentu a samostatná skóre pro pozitivní a negativní sentiment. Tato skóre umožňují přesněji rozlišit entitu na základě jejího emocionálního kontextu, což je užitečné pro identifikaci entit s komplexním nebo rozporuplným vyzněním.
Modul rovněž dokáže rozpoznat entity bez jasného sentimentu a označit je jako neutrální. Taková komplexní analýza poskytuje uživatelům cenné informace pro další zpracování a rozhodování, zejména při analýze velkých objemů textových dat.
Další možnosti modulu
Plná integrace modulu do softwaru IBM SPSS Statistics obohacuje možnosti analýzy strukturovaných dat o nové informace z dat nestrukturovaných.
Vlastní zpracování textu se neprovádí na serveru či klientské stanici, kde je nainstalován IBM SPSS Statistics, nýbrž textová data se zabezpečeně posílají na vzdálený textminingový server, kde jsou umístěny rozsáhlé lingvistické zdroje a výkonné procedury pro zpracování textů v přirozených jazycích.