Testovanie závislosti sentimentu filmového komentára a počtu hviezdičiek

V predchádzajúcom článku sme si predstavili štandardné výstupy z analýzy sentimentu na dátach filmových komentárov priradených užívateľmi k jednotlivým filmom na webovej stránke www.csfd.cz. Z analýzy sentimentu je vidieť, že máme už k dispozícii viacero premenných (číselné aj kategorickú), ktoré vypovedajú o sentimente komentára a môžeme tak prejsť k overovaniu hypotézy závislosti medzi počtom hviezdičiek a komentárom pomocou bežne používaných štatistických metód. Prístupov existuje viac, ukážeme si celkovo tri (Pearsonov lineárny korelačný koeficient, analýzu rozptylu a chí-kvadrát test v kontingenčných tabuľkách).
Testovanie závislosti
Ak budeme počet hviezdičiek považovať za číselnú premennú, graficky si vzťah celkového skóre sentimentu a počtu hviezdičiek môžeme graficky znázorniť pomocou bodového grafu (Obrázok 1), kde sme opäť kvôli prehľadnosti body mierne rozptýlili a ofarbili podľa kategórie sentimentu. Podľa očakávania je viditeľný rastúci lineárny trend celkového skóre sentimentu s narastajúcim počtom hviezdičiek a teda prevažujúcou kategóriou pozitívneho sentimentu.
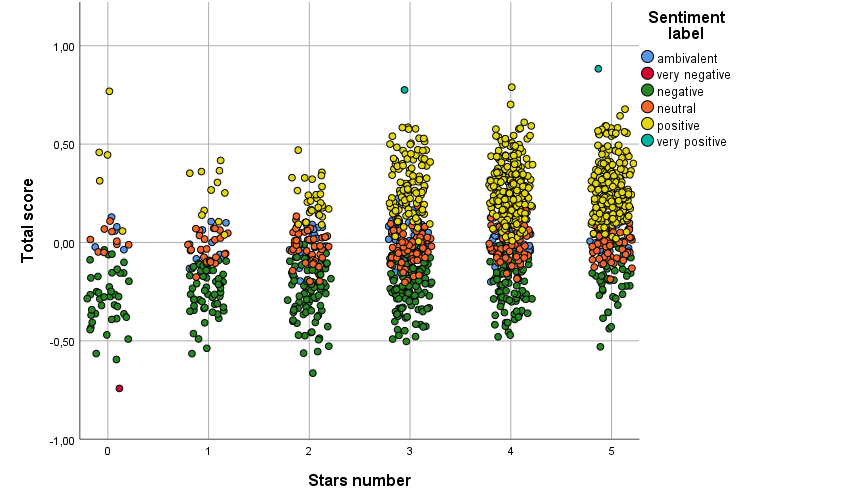
Štatisticky by sme existenciu lineárnej závislosti overili napríklad pomocou Pearsonovho lineárneho korelačného koeficientu (Obrázok 2). Podľa očakávania je hodnota korelačného koeficientu kladná a štatisticky významná na 5 % hladine významnosti, t.j. zamietame nulovú hypotézu nulovosti korelačného koeficientu.
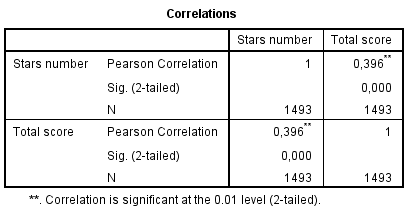
Obrázok 2: Pearsonov lineárny korelačný koeficient
Ak budeme počet hviezdičiek považovať za kategorickú premennú, graficky si vzťah celkového skóre sentimentu a počtu hviezdičiek môžeme graficky znázorniť pomocou stĺpcového grafu priemerov (Obrázok 3). Opäť podľa očakávania je viditeľný rastúci trend priemerného celkového skóre sentimentu s narastajúcim počtom hviezdičiek a pre počet hviezdičiek menší ako tri je priemerné skóre záporné.
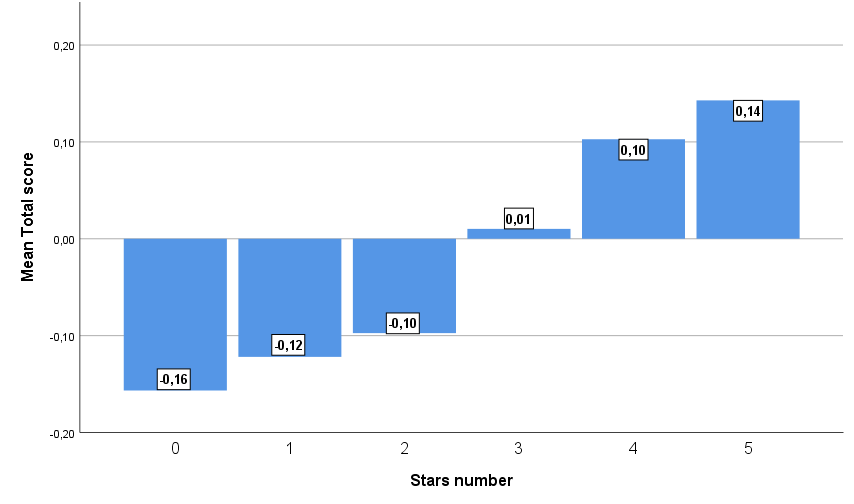
Pre overenie závislosti môžeme v tejto situácii použiť analýzu rozptylu, ktorá testuje nulovú hypotézu, že priemerné celkové skóre sentimentu je rovnaké vo všetkých kategóriách počtu hviezdičiek oproti alternatívnej hypotéze, že existuje aspoň jedna dvojica kategórií počtu hviezdičiek, pre ktorú sa priemerné celkové skóre líši. Jedným z predpokladov použitia je aj test zhody rozptylov v porovnávaných skupinách (Obrázok 4). Na 5 % hladine významnosti nezamietame nulovú hypotézy, že by sa rozptyly líšili v skupinách počtu hviezdičiek.

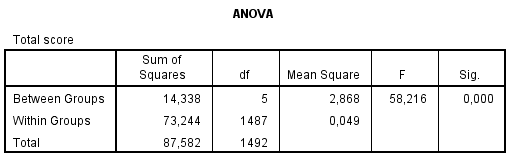
Z tabuľky analýzy rozptylu (Obrázok 5) podľa očakávania na 5 % hladine významnosti zamietame nulovú hypotézu zhody priemerného celkového skóre v skupinách počtu hviezdičiek. Ďalej by sme mohli zaujímať a testovať medzi ktorými dvojicami kategórií sa priemerného celkové skóre líši pomocou Post Hoc testov. Nie je to však našim cieľom, takže sa tomu venovať nebudeme.
Ak by sme chceli overiť existenciu závislosti medzi dvojicou kategorických premenných počet hviezdičiek a kategória sentimentu, môžeme využiť chí-kvadrát test v kontingenčných tabuľkách. Z kontingenčnej tabuľky riadkových percent (Obrázok 6), kde sú pre prehľadnosť ofarbené stĺpce (modrou farbou nižšie hodnoty a červenou vyššie v danom stĺpci), je opäť podľa očakávania vidieť, že negatívny sentiment je viac zastúpený pre menší počet hviezdičiek (nula až dva) a pozitívny sentiment pre väčší počet hviezdičiek (štyri až päť). Ambivalentný sentiment je skôr zastúpený pre počet hviezdičiek dva až štyri a neutrálny sentiment je pomerne rovnomerne zastúpený medzi počtami hviezdičiek.
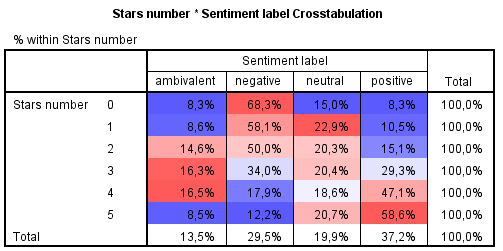
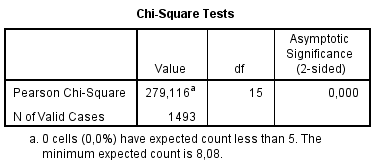
Na základe chí-kvadrát testu (Obrázok 7) zamietame na 5 % hladine významnosti nulovú hypotézu nezávislosti počtu hviezdičiek a kategórie sentimentu. Predpoklady testu sú tiež podľa poznámky pod tabuľkou splnené. Ďalej by sme sa mohli zaujímať, ktoré bunky kontingenčnej tabuľky nám narúšajú predpoklad nezávislosti pomocou znamienkovej schémy. Nie je to však našim cieľom, takže sa tomu venovať nebudeme.
Záverom tejto analýzy môžeme povedať, že všetky prezentované grafy, tabuľky a štatistické testy nám potvrdzujú existenciu závislosti medzi počtom hviezdičiek a komentárom, ktoré užívatelia priraďujú k filmom, a to v tom duchu, že čím vyšší počet hviezdičiek, tak tým pozitívnejší komentár.
Analýza sentimentu v IBM SPSS Statistics
Všetky prezentované výstupy a závery pochádzajú zo softvéru IBM SPSS Statistics. Aby ste však mohli realizovať analýzu sentimentu potrebujete si zakúpiť samostatný modul Acrea Text Analytics s procedúrou Sentiment. Tá sa jednoducho nainštaluje do softvéru IBM SPSS Statistics a pod menu Custom pribudne nová procedúra ACREA TA Sentiment (Obrázok 8).
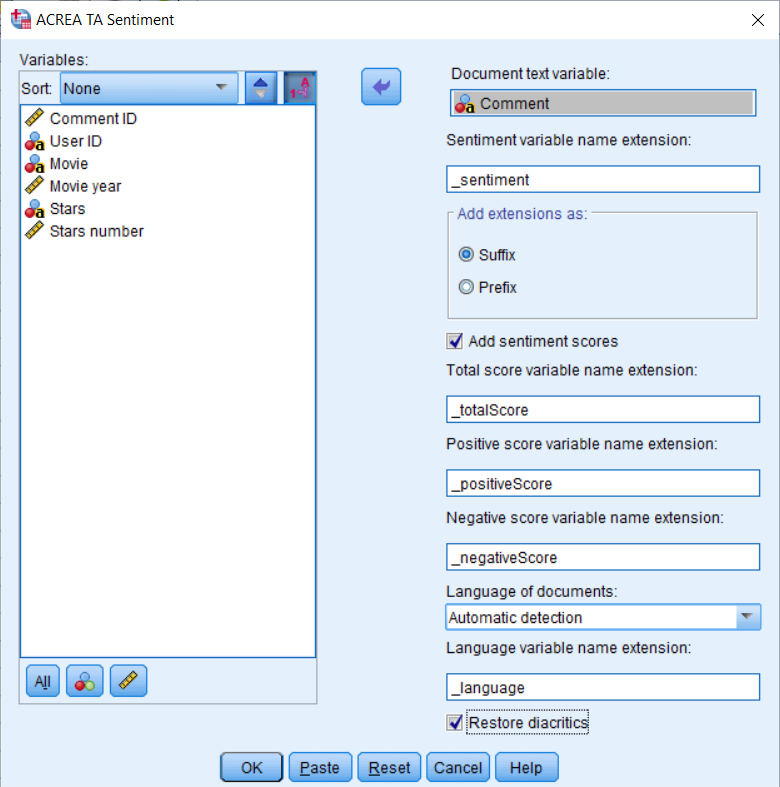
Obrázok 8: Procedúra ACREA TA Sentiment
Zadávanie je štandardné ako ste zvyknutý z iných procedúr. Procedúra umožňuje do dátovej matice pridať celkovo až päť nových premenných. Konkrétne identifikovaný jazyk analyzovaného textu pri automatickej detekcii, kategória sentimentu (ambivalentný, veľmi negatívny, negatívny, neutrálny, pozitívny, veľmi pozitívny), celkové skóre sentimentu (z intervalu od -1 do 1), čiastkové skóre pre pozitívny sentiment (z intervalu od 0 do 1) a čiastkové skóre pre negatívny sentiment (z intervalu od -1 do 0). Primárne je procedúra určená na analýzu českého prípadne slovenského textu avšak umožňuje aktuálne analyzovať aj texty z iných jazykov ako je angličtina a nemčina. Pre český jazyk je možné pred samotnou analýzou sentimentu tiež realizovať automatizované nahradenie diakritiky pokiaľ chýba. Súčasťou je aj dokumentácia pod tlačidlom Help, ktorá sa zobrazí vo webovom prehliadači a je z nej zrejmé čo jednotlivé políčka a nastavenia procedúry znamenajú (Obrázok 9).
Procedúra má tiež aj svoju vlastnú syntax ACREA TA SENTIMENT (Obrázok 10) a je tak možné ju využiť pri automatizácii procesov na pravidelnej báze.

Obrázok 10: Syntax
Úplným záverom je možné povedať, že analýza sentimentu má svoje využitie všade tam, kde je potrebné analyzovať postoje a názory vyjadrené voľným textom. Napríklad analyzovať komentáre zo sociálnych médií ako je Facebook, Youtube, Instagram, Twitter, rôznych diskusných fór, otvorených otázok v dotazníkoch atď.
Potřebujete poradit, jak využívat vaše data? Chcete zefektivnit a urychlit vaši práci? Nevíte, jaký software je pro vaše řešení ten správný? Využijte naši nezávaznou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení.

