Vyhodnocovanie kvality modelu klasifikácie viacerých tried

Pri vyhodnocovaní kvality modelu binárnej klasifikácie (binary classification) sa využívajú rôzne evaluačné metriky (evaluation metrics). Napríklad Accuracy, Precision, Recall, F1 score, Area Under the ROC Curve (AUC), Log loss atď. V tomto článku sa zameriame na vyhodnocovanie kvality modelu klasifikácie viacerých tried (multi-class classification). Cieľom článku je ukázať ako je možné tieto známe evaluačné metriky pre model binárnej klasifikácie využiť pri vytvorení obdobných evaluačných metrík rôznymi možnosťami pre model klasifikácie viacerých tried. Pre jednoduchosť to bude predstavené iba s využitím evaluačnej metriky Precision. Ostatné evaluačné metriky sa dajú aplikovať obdobným spôsobom. Keďže softvér IBM SPSS Modeler priamo neposkytuje evaluačné metriky pre model klasifikácie viacerých tried (s výnimkou evaluačnej metriky Accuracy), ukážeme si ako je možné pomerne jednoducho ich tam implementovať. Ukážeme si tiež ako jednoducho je to realizovateľné v programovacom jazyku Python, keďže tento nástroj je v súčasnosti najpoužívanejším a aj najobľúbenejším v oblasti data science a strojového učenia (machine learning).
Evaluačná metrika Precision pre model binárnej klasifikácie
Pre model binárnej klasifikácie, t.j. klasifikácie dvoch tried (pozitívnej a negatívnej), je evaluačná metrika Precision definovaná ako
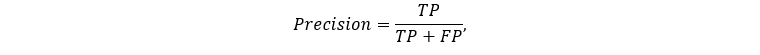
kde TP (True Positive) je počet správne predikovaných v skutočnosti pozitívnych prípadov modelom a FP (False Positive) je počet nesprávne predikovaných v skutočnosti negatívnych prípadov. Čiže menovateľ evaluačnej metriky Precision odpovedá počtu predikovaných pozitívnych prípadov.
Predstavme si, že máme vytvorený model na predikciu malígneho melanómu (pozitívna trieda). Na základe testovacích dát model správne identifikuje 9 malígnych melanómov z 10 a 95 benígnych zo
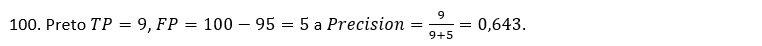
To znamená, že náš model sa nemýli v 64,3 % prípadov, pri ktorých model predikuje malígny melanóm.
Evaluačná metrika Precision pre model klasifikácie viacerých tried
Existujú tri rôzne možnosti výpočtu evaluačnej metriky Precision (obdobne pre iné metriky) pre model klasifikácie viacerých tried
- Macro Averaged Precision
Pre každú triedu samostatne vypočítame evaluačnú metriku Precision a potom ich spriemerujeme. - Micro Averaged Precision
Pre každú trieduvypočítame TP a FP a potom vypočítame celkovú Precision, t.j. súčet TP jednotlivých tried podelíme súčtom TP a FP jednotlivých tried. Čitateľ je teda rovný počtu správne predikovaných prípadov a menovateľ celkovému počtu predikovaných prípadov. Micro Averaged Precision nie je nič iné ako podiel správne predikovaných prípadov a teda evaluačná metrika známa ako Accuracy. - Weighted Precision
Podobné ako Macro Averaged Precision avšak evaluačné metriky pre jednotlivé triedy spriemerujeme vážene. Ako váhy budú použité skutočné počty prípadov v jednotlivých triedach.
Predstavme si, že máme vytvorený model na predikciu stupňa popularity článku. Stupeň popularity (jednotlivá trieda) môže mať hodnotu 0, 1 a 2. Pre jednoduchosť uvažujme, že na 10 testovacích článkoch sú skutočné stupne popularity jednotlivých článkov zapísané vo forme zoznamu nasledovne
[1, 2, 0, 2, 2, 0, 1, 2, 1, 0]
a predikcie modelom sú vo forme zoznamu v odpovedajúcom poradí zapísané nasledovne
[1, 1, 0, 2, 1, 2, 1, 2, 2, 2]
Teraz môžeme vypočítať TP a FP jednotlivých tried a tiež skutočné početnosti jednotlivých tried (označíme ako N). Indexom budeme označovať informáciu o tom, že o ktorú triedu sa jedná. Výsledky sú nasledovné

a teda jednotlivé evaluačné metriky pre Precision sú nasledovné

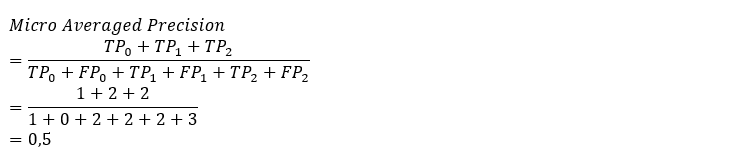

Ak by sme mali odpovedať na otázku, ktorý prístup výpočtu voliť, tak to nie je jednoznačné. Závisí to najmä od riešeného problému. Vo všeobecnosti sa však dá povedať a vyplýva to z jednotlivých prístupov, že pokiaľ nie je približne rovnaké zastúpenie jednotlivých tried avšak všetky triedy sú pre nás rovnako dôležité, prístup Macro Averaged sa javí ako vhodnejší, keďže každá trieda má rovnakú váhu vo výpočte. Pokiaľ však nie je približne rovnaké zastúpenie jednotlivých tried avšak chceme priradiť vyššiu/nižšiu dôležitosť triedam s vyšším/nižším zastúpením v dátach, tak prístup Weighted sa javí ako vhodnejší, pretože každá trieda má vo výpočte váhu odpovedajúcu početnosti jednotlivých tried. Ak je rovnaké zastúpenie jednotlivých tried, tak prístupy Macro Averaged a Weighted sú totožné. V prípadne, že nie je približne rovnaké zastúpenie jednotlivých tried, tak v prístupe Micro Averaged bude prevažujúca trieda dominovať vo výpočte.
Implementácia v IBM SPSS Modeler
Keďže evaluačné metriky pre model klasifikácie viacerých tried nie sú priamo implementované v IBM SPSS Modeler (s výnimkou evaluačnej metriky Accuracy v uzle Analysis), je potrebné si ich tam napočítať. V postupnosti krokov si to ukážeme na rovnakých dátach na vstupe ako sme uvažovali vyššie a evaluačnej metrike Precision. Nebudeme teda ani ošetrovať situáciu ak by náhodou model neposkytoval predikciu niektorej triedy. Je to však možné jednoducho upraviť. Napríklad podobne ako to má riešené knižnica scikit-learn v programovacom jazyku Python. Po jednom vyhotovení stačí celý proces výpočtu evaluačnej metriky rôznymi spôsobmi zabaliť do superuzla (mimo uzla User Input) a použiť na reálne dáta s tým, že musia byť rovnako nazvané vstupné názvy premenných (v našom príklade target_true a target_prediction). Jednotlivé kroky procesu tvorby nebudeme špeciálne komentovať, keďže to odpovedá iba implementácii krokov už používaných vyššie a z obrázkov je to zrejmé. Celý proces vyzerá nasledovne

Jednotlivé kroky procesu sú nasledovné
1.Uzlom User Input vytvoríme a naplníme dve nové premenné s testovacími dátami
2.Uzlom Derive vytvoríme novú premennú a zapojíme za predchádzajúci uzol
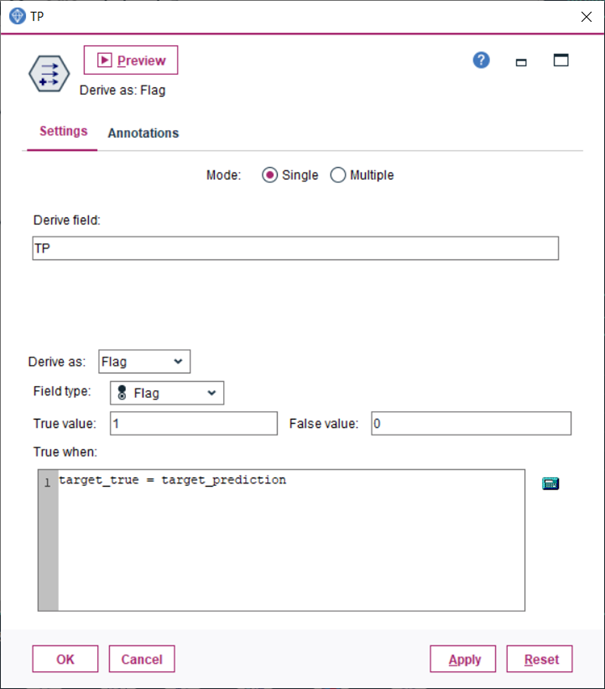
3.Uzlom Derive vytvoríme novú premennú a zapojíme za predchádzajúci uzol
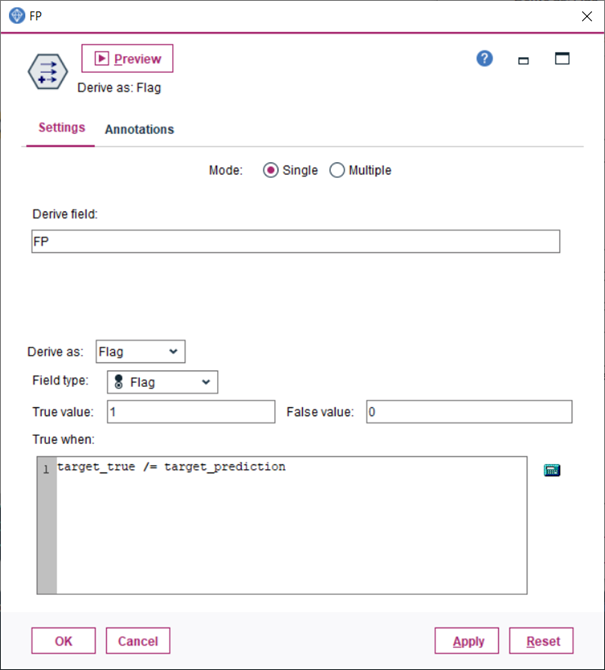
4.Urobíme dve agregácie uzlom Aggregate, ktoré zapojíme za predchádzajúci uzol
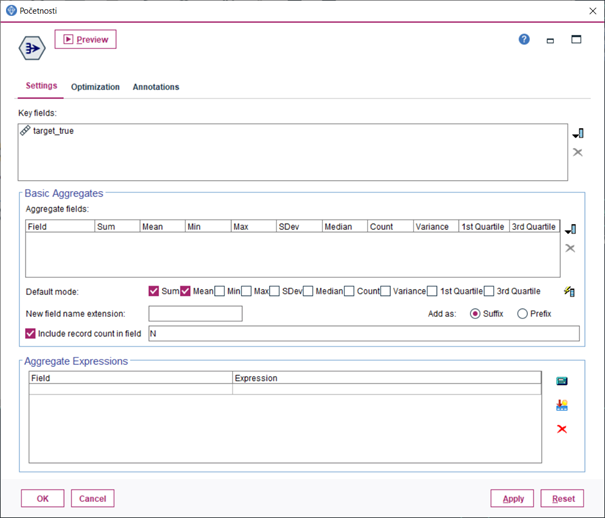
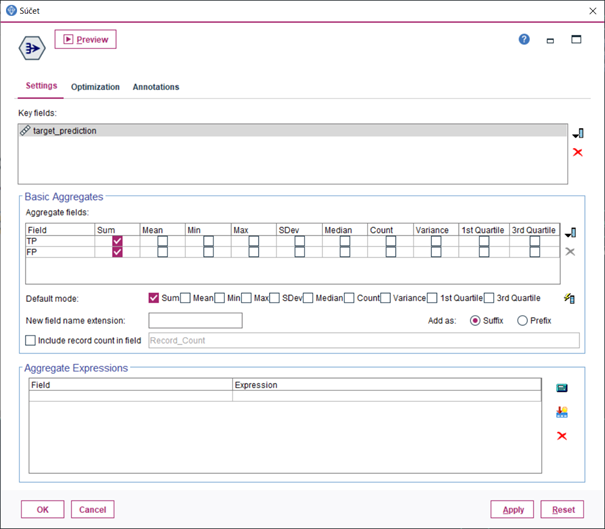
5.Dvoma uzlami Filter, ktoré zapojíme za predchádzajúce uzly premenujeme premennú target_true a target_prediction na trieda
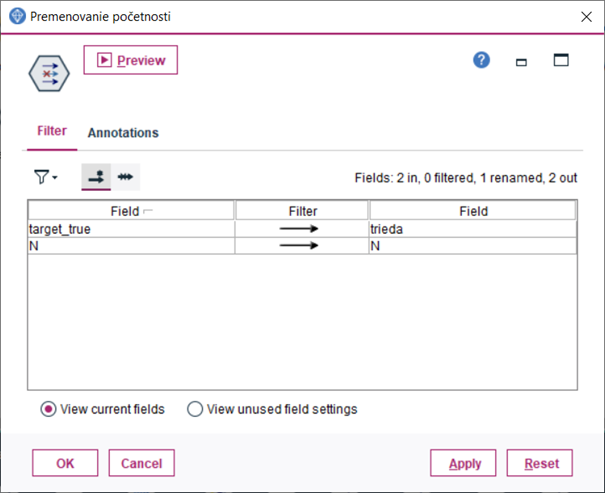
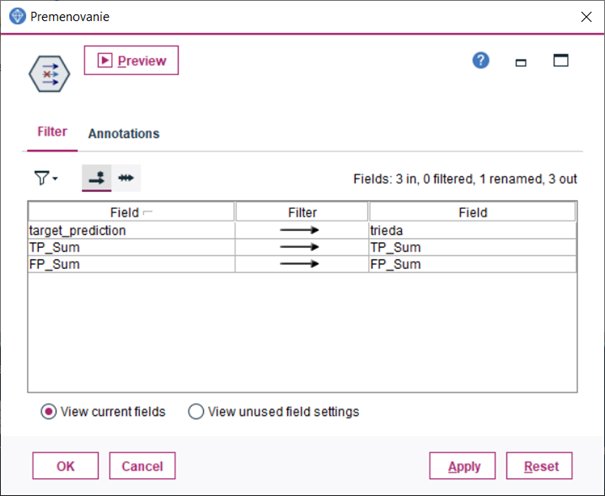
6.Obidve vetvy z predchádzajúceho kroku spojíme uzlom Merge
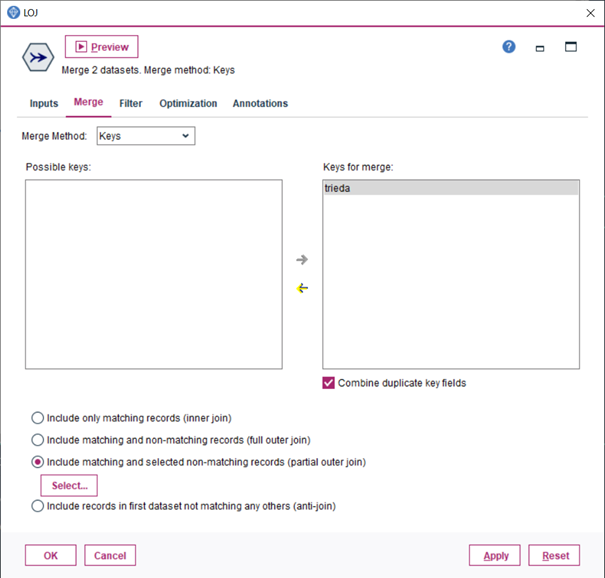
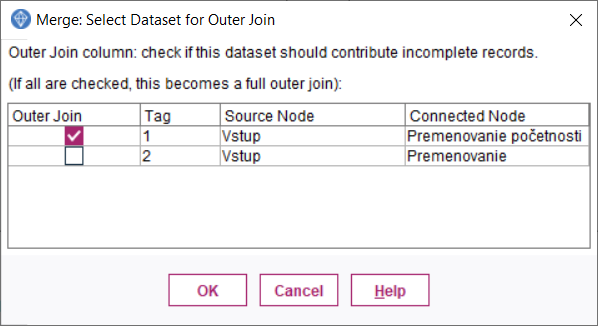
7.Uzlom Derive vytvoríme novú premennú a zapojíme za predchádzajúci uzol
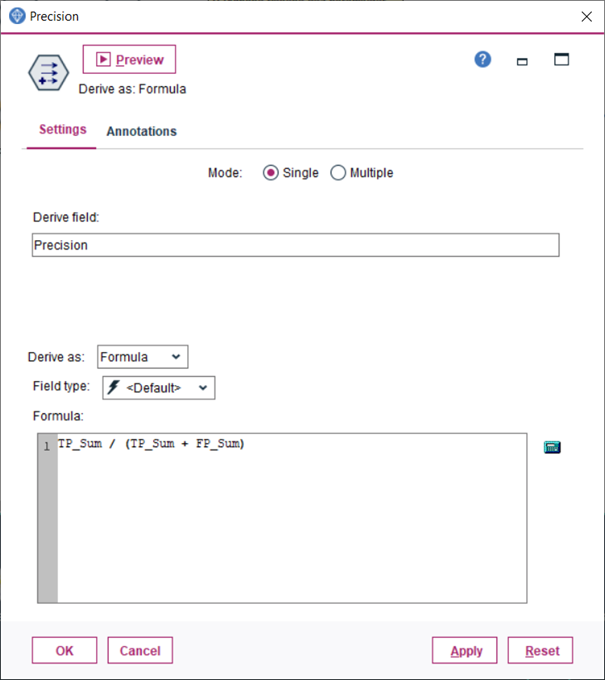
8.Uzlom Derive vytvoríme novú premennú a zapojíme za predchádzajúci uzol
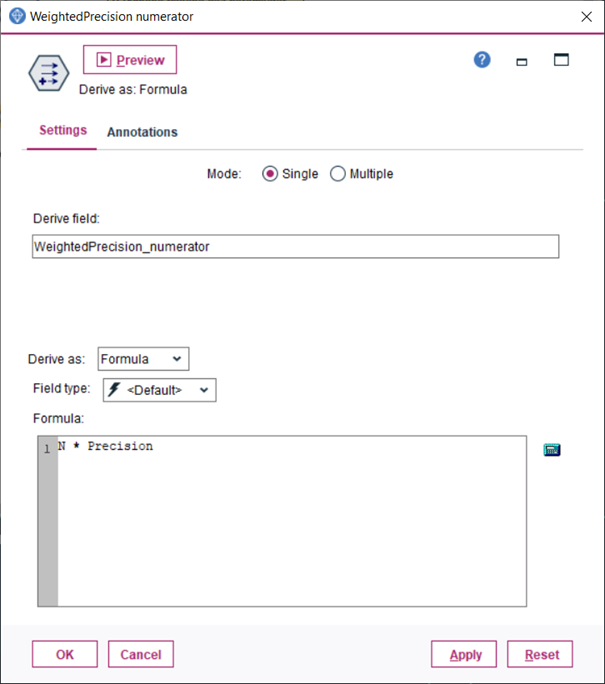
9.Urobíme agregáciu uzlom Aggregate, ktorý zapojíme za predchádzajúci uzol
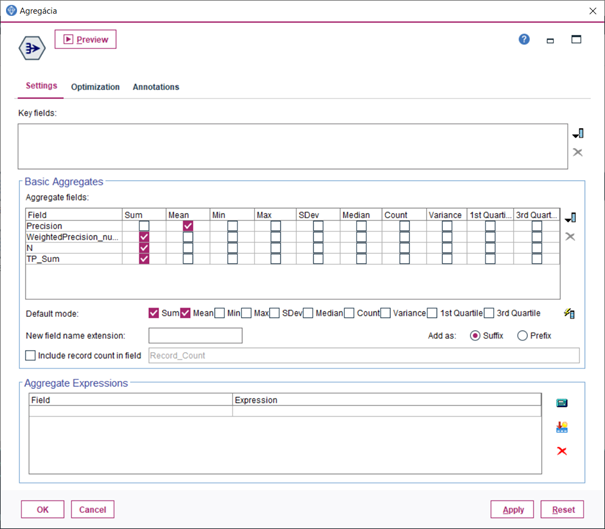
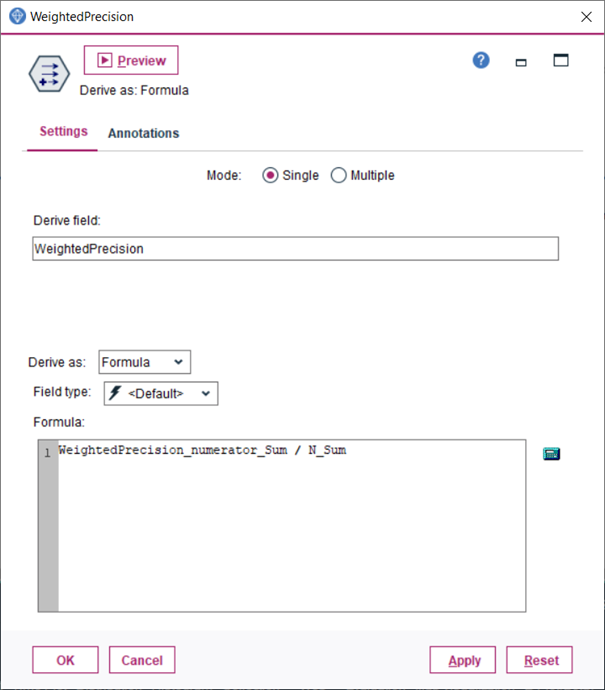
10.Uzlom Derive vytvoríme novú premennú a zapojíme za predchádzajúci uzol
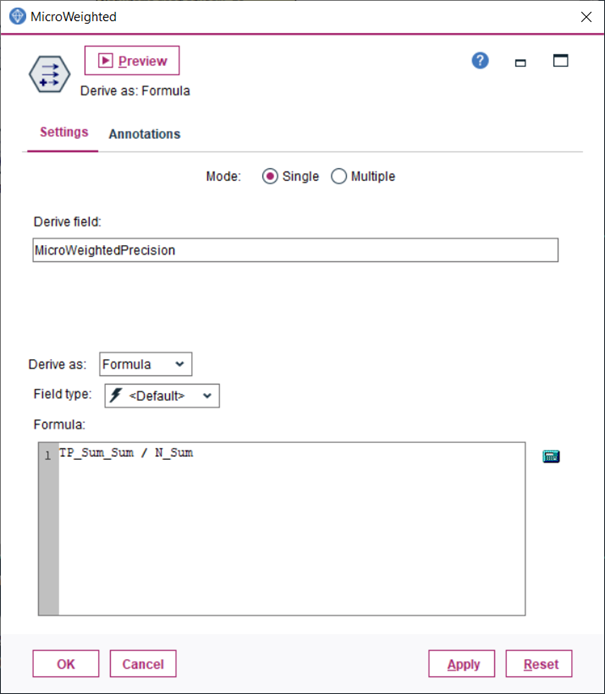
11.Uzlom Derive vytvoríme novú premennú a zapojíme za predchádzajúci uzol
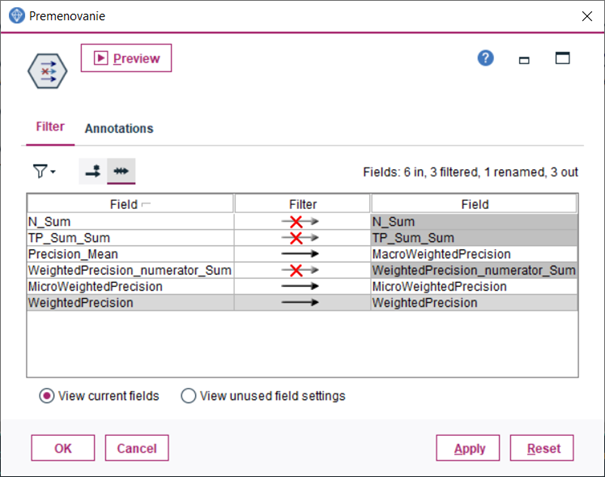
12.Uzlom Filter, ktorý zapojíme za predchádzajúci uzol, premenujeme a odfiltrujeme nepotrebné premenné
13.Uzol Table zapojíme za predchádzajúci uzol a spustíme pravým tlačidlom a výberom možnosti Run
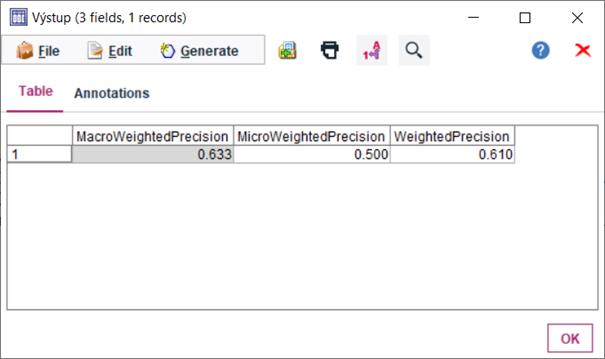
Z posledného obrázku vidíme, že výsledky sú rovnaké ako sme uvádzali vyššie. Nejaký čas síce zaberie implementácia v IBM SPSS Modeler avšak ďalšie opakované využívanie pri rôznych úlohách je už len otázka maximálne jednej minúty.
Implementácia v programovacom jazyku Python
Implementácia v programovacom jazyku Python je jednoduchšia ak to nechceme programovať úplne od začiatku. K dispozícii je knižnica pre strojové učenie scikit-learn (potrebné nainštalovať ak nie je súčasťou distribúcie), ktorá okrem iného obsahuje aj evaluačné metriky pre model klasifikácie viacerých tried. Pre evaluačnú metriku Precision počítanú rôznymi spôsobmi, na rovnakých dátach na vstupe ako sme uvažovali vyššie, sú príkazy s výstupmi nasledovné

Z obrázka vidieť, že výsledky sú opäť rovnaké.
Rádi byste se o statistice a analýze dat dozvěděli více? Chcete se stát mistrem ve svém oboru nebo si jen potřebujete doplnit znalosti? V ACREA nabízíme širokou nabídku kurzů pro váš profesní růst. Máte-li jiný dotaz. Nebojte se využít naši nezávaznou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení.

