Rozšírenie funkcionality IBM SPSS Statistics o procedúry PS – 2. část

V tomto článku sa zameriame na zvyšné procedúry z ponuky Predictive solutions – Analyze, ktoré nám poskytnú informácie o mierach disparít, ďalej na ohodnotenie zhlukov vytvorených zoskupovacou analýzou a porovnávanie obsahu dvoch textových premenných.
Inequality measures
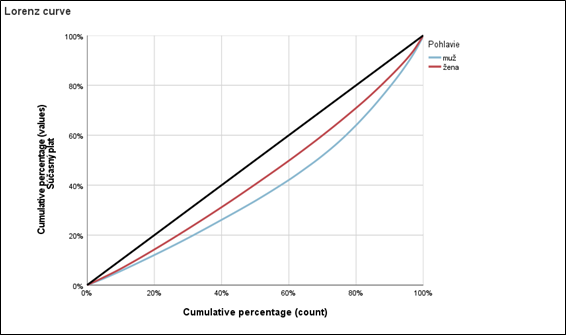
Procedúra počíta Lorenzovu krivku znázorňujúcu percentuálny podiel ľudí na celkovom bohatstve. Lorenzova krivka je známy nástroj pre grafické znázornenie nerovnomerného bohatstva v spoločnosti. Výstupom procedúry je vykreslenie grafu Lorenzovej krivky pre navolené skupiny a taktiež tabuľka s vybranými indexami nerovností.

Cluster evaluation
Procedúra slúži k ohodnoteniu zhlukov vytvorených zoskupovacou analýzou. Procedúra umožňuje uložiť do dátovej matice hodnotu siluety pre každé pozorovanie, hodnotu vzdialenosti pozorovania od stredu zhluku a identifikátora najbližšieho zhluku.
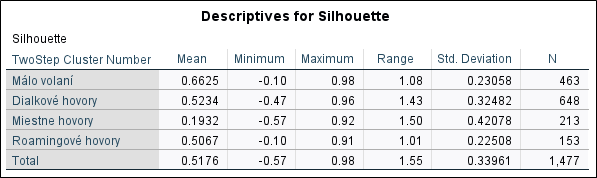
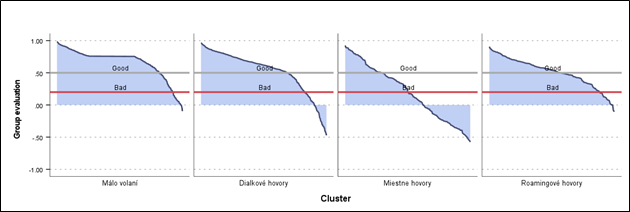
Hodnota koeficientu siluety sa pohybuje v intervale (-1, 1). Čím je hodnota koeficientu bližšia k jednej, tým lepšia je kvalita triedenia. Vo všeobecnosti platí, že hodnota väčšia ako 0,5 znamená dobré triedenie dát.
Výstupom procedúry sú viaceré objekty:
- Silhouette mean – hodnota siluety (graf s celkovou hodnotou siluety)
- Descriptive statistics for Silhouette – popisné štatistiky pre hodnoty siluety
- Distribution of Silhouette values by cluster – rozdelenie hodnôt siluety v jednotlivých klastroch
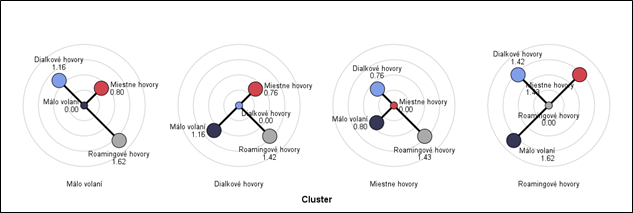
- Distances between clusters centroids – vzdialenosti medzi centroidmi klastrov
- The distance between case and cluster centroid – vzdialenosť medzi prípadom a centroidom klastra

Compare text
Procedúra porovnáva obsah dvoch textových premenných a umožňuje uložiť skóre a ich podobnosť do dátovej matice a poskytuje nasledujúce miery pre textové premenné:
- Jaro Distance
- Jaro-Winkler Distance
- Hamming Distance
- Levenshtein Distance
- Optimal Streing Alignment
- Needleman-Wunsch
- Longest Common Substring
Score
Pridá hodnotenie vzdialenosti medzi analyzovanými textami pre všetky vybrané miery vzdialenosti. Napríklad pre miery Hamming, Levenshtein a Optimal String Alignment sa jedná o počet odlišných znakov. Naopak u Jaro a Jaro-Winkler ide o počet zhodných znakov. Novo pridané premenné majú príponu _scr.
Similarity
Pridá normalizované hodnoty podobnosti (v intervale 0 – 1). Čím bližšia bude hodnota k jednej, tým viacej sú si porovnávané reťazce podobné. Novo pridané premenné majú príponu _sim.
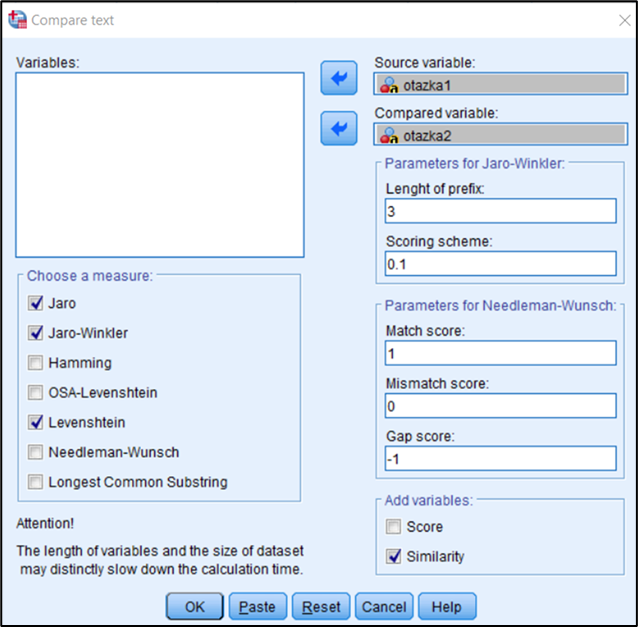
Procedúra vyžaduje k analýze dve textové premenné a z ponuky mier vzdialenosti musí byť vybraná aspoň jedna možnosť a aspoň jeden typ premennej zo sekcie Add variables. Ako už býva zvykom, všetky predstavené procedúry majú vlastnú syntax a help.

