Rozhodovací stromy – pomocník při hledání předpovědi
Vědět dostatečně dopředu, zda něco nastane nebo ne, je velmi užitečné. Můžeme se účinně pokusit události, pokud je nepříznivá zabránit nebo se na ni alespoň připravit. Problém ale je, jak budoucí vývoj předpovědět. Jednou z možností je poučit se o budoucnosti z minulosti.
Statistika a data mining řeší velké množství úloh tohoto typu. Na základě historických údajů se pokoušejí nalézt obecné zákonitosti, kvantifikovat je statistickým modelem, interpretovat je a případně použít k předpovědi. Předpovídané vlastnosti se říká vysvětlovaná nebo cílová proměnná a ostatním vlastnostem vysvětlující proměnné nebo prediktory. Přístup k úloze je ovlivněny typem proměnných zejména typem cílové proměnné.
Proměnná může být číselná proměnná (například výška nebo příjem) nebo kategorizovaná (například typ výrobku nebo oblíbená značka). Zvláštním případem kategorizované proměnné je proměnná se dvěma hodnotami (binární proměnná), nejčastěji jde o nastoupení nebo nenastoupení určité události (například odchod zákazníka nebo úspěšné ukončení studia).
Například předpovídáme, zda student úspěšně dokončí školu na základě vlastností, které o něm známe již na začátku studia. Model se odhadne na souboru bývalých studentů, u kterých už známe i jejich výsledky studia. Model pak interpretujeme a použijeme pro odhad úspěšnosti současných studentů.
K řešení úloh tohoto typu bylo nalezeno mnoho statistických algoritmů, každý přistupuje k úloze jiným způsobem. Často je volba algoritmu omezena tím, zda je cílová proměnná číselná, kategorizovaná nebo binární. Správný algoritmus pro konkrétní úlohu lze nalézt jen experimentem.
Jedním z obecně úspěšných algoritmů jsou klasifikační a asociační stromy. Mají několik výhod.
- Jsou univerzální – můžeme je použít, pokud je cílová proměnná i číselná, kategorizovaná i binární. Také vlastnosti použité k předpovědi mohou být číselné proměnné (např. věk, příjem), kategorizované proměnné (např. pohlaví, typ předcházející školy) nebo binární (např., pohlaví, vlastní/nevlastní automobil).
- Obvykle vedou k dobrým odhadům – ačkoliv to to nelze říci obecně, většinou se dá daná úloha s použitím stromů úspěšně vyřešit.
- Jsou interpretovatelné – odhadnutý model dává nejen předpovědi, ale dovoluje, abychom předpovědím porozuměli, což není u mnoha jiných algoritmů možné.
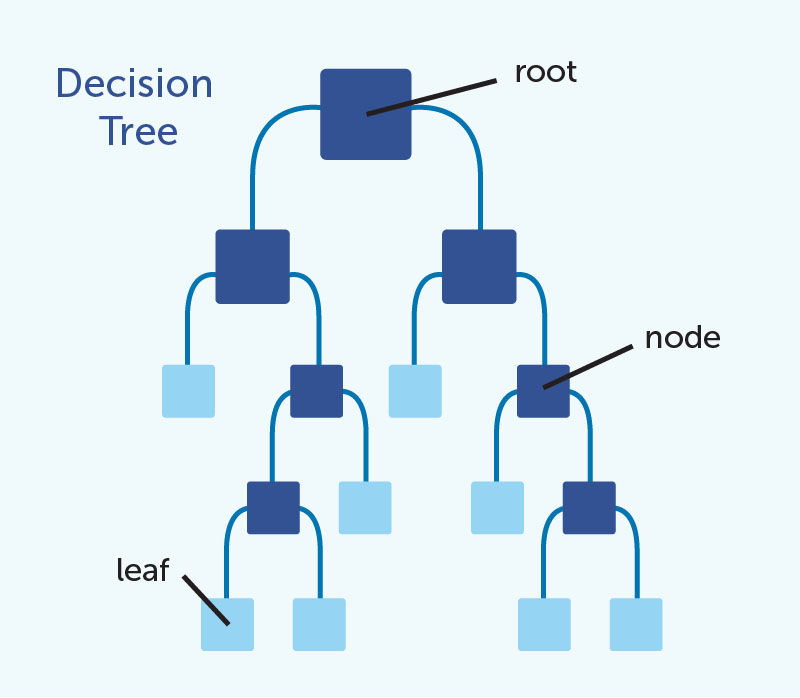
 Algoritmus stromu rozděluje soubor na části, ve kterých se cílová proměnná chová velmi jednoduše. Číselná cílová proměnná je v každé části souboru téměř konstantní, kategorizovaná nabývá převážně jedné kategorie. Dělení se děje hierarchicky, soubor je nejprve rozdělen na skupiny a pak je každá z nich dělena samostatně nezávisle na jiných skupinách. Rozdělování se děje podle hodnot prediktorů, např. se jedna část rozdělí podle pohlaví a jiná podle věku. Algoritmus sám hledá, jaké dělení je pro danou část nejvhodnější a zda se vůbec má skupina dělit. Výsledkem dělení je graf, kterému se říká strom.
Algoritmus stromu rozděluje soubor na části, ve kterých se cílová proměnná chová velmi jednoduše. Číselná cílová proměnná je v každé části souboru téměř konstantní, kategorizovaná nabývá převážně jedné kategorie. Dělení se děje hierarchicky, soubor je nejprve rozdělen na skupiny a pak je každá z nich dělena samostatně nezávisle na jiných skupinách. Rozdělování se děje podle hodnot prediktorů, např. se jedna část rozdělí podle pohlaví a jiná podle věku. Algoritmus sám hledá, jaké dělení je pro danou část nejvhodnější a zda se vůbec má skupina dělit. Výsledkem dělení je graf, kterému se říká strom.
Ten zachycuje, jak se postupně soubor dělí na menší a menší části. Existuje několik druhů algoritmu, které se liší tím, jaká kritéria pro rozdělování používají, ale obecný princip je stejný.
Rádi byste se o statistice a analýze dat dozvěděli více? Chcete se stát mistrem ve svém oboru nebo si jen potřebujete doplnit znalosti? V ACREA nabízíme širokou nabídku kurzů pro váš profesní růst. Máte-li jiný dotaz. Nebojte se využít naši nezávaznou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení.

