Procedury pro přípravu dat: kontrola a ověřování kvality dat

V sérii čtyř na sebe navazujících článků si postupně představíme nástroje pro přípravu dat, které jsou ve verzi IBM SPSS Statistics 27 nově zařazené do základního modulu Base (dříve modul Data Preparation) a jsou tak nyní dostupné širokému okruhu uživatelů. V tomto článku si podrobněji přiblížíme procedury pro kontrolu a ověřování kvality dat, díky kterým si můžete značně usnadnit a urychlit práci při těchto činnostech.
Kontrola a čištění dat
Kvalitní příprava dat je nutnou podmínkou každé analýzy. Jedním z jejích kroků je čištění dat. V této fázi je třeba nejprve zkontrolovat jednotlivé proměnné a zaměřit se především na tyto oblasti:
- identifikace podezřelých, neobvyklých nebo chybných případů, proměnných a hodnot v datech,
- odhalení problematických rozložení proměnných (například řídce zastoupené kategorie, proměnná je konstantní nebo většina případů patří do jedné kategorie, výskyt extrémních hodnot apod.),
- vynechané hodnoty, jejich podíl a struktura,
- nekompletní nebo duplicitní ID případů.
Tam, kde jsou proměnné logicky provázané je rovněž třeba ověřit, zda jejich hodnoty vzájemně korespondují – pokud například respondent uvedl, že pobírá starobní důchod, měl by tomu odpovídat také jeho věk.
K čemu je určená nabídka Validation
Kontrolu a čištění dat lze v IBM SPSS Statistics provádět mnoha způsoby včetně využití základních statistických procedur jako například Descriptives, Frequencies apod. v kombinaci s grafy. Zde se zaměříme na procedury z nabídky Data, Validation, díky kterým lze tyto činnosti provádět rychleji a efektivněji.
Kromě základní validace je možné zde definovat tzv. pravidla a následně je vyhodnocovat. Tato pravidla vyjadřují podmínky, které by měla proměnná nebo skupina proměnných splňovat. Mohou se přitom vztahovat k jednotlivým proměnným (například: proměnná nabývá pouze celočíselných hodnot od 1 do 5), nebo charakterizovat vzájemné vztahy mezi více proměnnými.
Nabídka Validation obsahuje tři podnabídky, které si postupně představíme. Umožňují nahrát předdefinovaná pravidla pro kontrolu dat (Load Predefined Rules), vytvořit nebo upravit vlastní pravidla (Define Rules) a provést validaci dat (Validate Data).
Využití předdefinovaných pravidel
Pomocí nabídky Data, Validation, Load Predefined Rules lze nahrát předdefinovaná validační pravidla ze souboru Predefined Validation Rules.sav, který je součástí instalačního adresáře (… IBM\SPSS\Statistics\27\lang\en). Tento soubor obsahuje 23 předdefinovaných pravidel pro jednotlivé proměnné, většina z nich ale nemá v českém prostředí příliš uplatnění. Soubor Predefined Validation Rules.sav je však možné přepsat tak, aby obsahoval opakovaně užívaná pravidla podle konkrétních potřeb uživatele. Pomocí nabídky Data, Validation, Define Rules pravidla upravíme nebo vytvoříme nová vlastní a následně soubor znovu uložíme pod stejným názvem do stejné složky instalačního adresáře.
Zadání vlastních pravidel
Nabídka Data, Validation, Define Rules je určena k definování nebo modifikaci vlastních validačních pravidel.
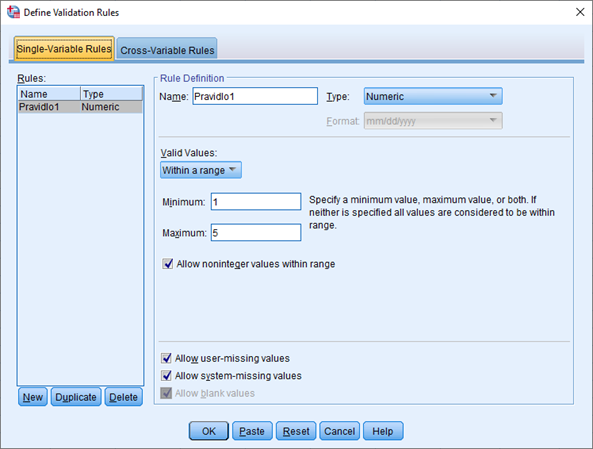
Na záložce Single-Variable Rules se zadávají pravidla, která se vztahují k jednotlivým proměnným (následně je však lze aplikovat na libovolný počet proměnných). Obvykle se jedná o omezení přípustných hodnot.
V poli Rules se zobrazují již definovaná pravidla. Pomocí tlačítek ve spodní části okna vytvoříme nové pravidlo (New), duplikujeme pravidlo pro následnou úpravu (Duplicate) nebo smažeme existující pravidlo(Delete).
Nové pravidlo definujeme v části Rule Definition. V poli Name zadáme název a v rozevíracím seznamu Type určíme typ proměnné, pro který je pravidlo určeno. V části Valid Values specifikujeme možné hodnoty pomocí rozpětí nebo jejich vypsáním. Podle typu proměnné dále určíme, zda jsou povolené neceločíselné hodnoty (Allow noninteger values within range), uživatelem definované vynechané hodnoty (Allow user-missing values), systémové vynechané hodnoty (Allow system-missing values) nebo prázdná pole (Allow blanc values).
Na záložce Cross-Variable Rules se zadávají pravidla, která dávají do souvislosti hodnoty více proměnných. Může se jednat například o kontrolu vztahu mezi věkem respondenta a pobíráním starobního důchodu.
Do pole Name zadáme název pravidla a v poli Logical Expression specifikujeme výraz, který má být splněn pro chybný případ. Pro zadání výrazu lze užít existující proměnné (Variables), tlačítka operátorů a funkce ze seznamu Function. Pokud některou z funkcí označíme, v poli Description se zobrazí její popis.
Validace dat
Pomocí nabídky Data, Validation, Validate Data nastavíme, které kontroly dat se mají provést, a následně je spustíme.
Na záložce Variables zadáme do pole Analysis Variables vstupní proměnné, kterých se budou kontroly týkat, a do pole Case Identifier Variables jednu nebo více proměnných identifikujících případy.
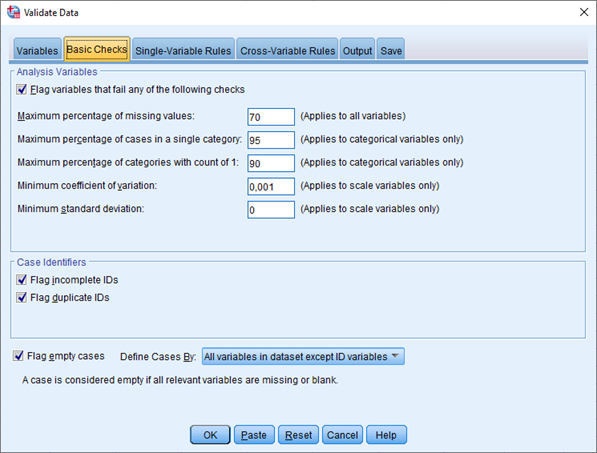
Na záložce Basic Checks označíme základní kontroly, které se mají provést a případně upravíme nastavené hodnoty.
Zaškrtávací políčko Flag variables that fail any of the following checks v části Analysis Variables určuje, zda se budou realizovat následující kontroly analyzovaných proměnných:
- Maximum percentage of missing values – procento vynechaných hodnot je vyšší než zadaná hodnota,
- Maximum percentage of cases in a single category – procento případů v jedné kategorii je vyšší než zadaná hodnota,
- Maximum percentage of categories with count of 1 – procento kategorií s četností 1 je vyšší než zadaná hodnota,
- Minimum coefficient of variation – variační koeficient je menší nebo roven zadané hodnotě,
- Minimum standard deviation – směrodatná odchylka je menší nebo rovna zadané hodnotě.
V části Case Identifiers volíme kontroly, které se vztahují k proměnným identifikujícím případy:
- Flag incomplete IDs – nekompletní identifikátory případů,
- Flag duplicate IDs – duplicitní identifikátory případů.
Při zaškrtnutí políčka Flag empty cases se označí prázdné případy. V poli Define Cases By zároveň určíme, jak jsou definovány prázdné případy (chybějí hodnoty všech proměnných v datech kromě ID nebo včetně ID).
Na záložce Single-Variable Rules se v poli Analysis Variables zobrazuje přehled proměnných a jejich základní vlastnosti (graf rozložení, minimum, maximum a počet aplikovaných pravidel) a v poli Rules definovaná jednoduchá pravidla. Pro každou proměnnou samostatně označíme pravidla, jejichž kontrola se pro ni má provést. Pomocí zaškrtávacího políčka Limit number of cases scanned lze omezit počet případů, z nichž se načítají informace o proměnných.
Záložka Cross-Variable Rules obsahuje v části Rules přehled definovaných pravidel, která dávají do souvislosti hodnoty více proměnných. Zvolíme, která z nich se mají aplikovat (defaultně jsou označena všechna).
Na záložce Output zadáme požadované výstupy.
Zaškrtávací políčko List validation rule violations by case v části Casewise Report určuje, zda se zobrazí přehled porušených pravidel uspořádaný podle jednotlivých případů. Přitom lze nastavit následující omezení:
- Minimum Number of Violations for a Case to be Included – minimální počet porušených pravidel u zahrnutých případů,
- Maximum Number of Cases in Report – maximální počet případů uvedených v přehledu.
V části Single-Variable Validation Rules volíme výstupy pro jednoduchá pravidla:
- Summarize violations by analysis variables – přehled porušených pravidel organizovaný podle proměnných,
- Summarize violations by rule – přehled porušených pravidel uspořádaný podle pravidel.
Zaškrtávací políčko Display descriptive statistics for analysis variables umožňuje zobrazit přehled popisných statistik analyzovaných proměnných (tabulka četností nebo popisných statistik podle typu proměnné).
Při označení políčka Move cases with validation rule violations to the top of the active dataset budou případy porušující některé z pravidel přesunuty na začátek datového souboru.
Na záložce Save volímeinformace, které mají být uloženy do datové matice jako nové proměnné.
V části Summary Variables lze označit následující sumární proměnné:
- Empty case indicator – indikátor vyjadřující chybějící identifikaci případu,
- Duplicate ID Group – duplicitní identifikace případu,
- Incomplete ID indicator – indikátor nekompletní identifikace případu,
- Validation rule violations (total count) – celkový počet porušených pravidel u případu.
Dále určíme, zda mají být nahrazeny všechny dříve vytvořené sumární proměnné (Replace existing summary variables).
Zaškrtávací políčko Save indicator variables that record all validation rule violations určuje, zda se pro každé pravidlo vytvoří indikační proměnná, vyjadřující jeho porušení.
Výstupy
První dvě procedury jsou určené pro zadání pravidel a nemají tedy žádné výstupy. Výstupem procedury pro validaci dat jsou různé typy přehledů o proběhlých kontrolách, porušených pravidlech a o případech, u nichž k porušení došlo. Pokud jsme tak označili v zadání, vytvoří se rovněž nové proměnné v datové matici, které indikují jednotlivé typy problémů a/nebo celkový počet porušených pravidel u případu. Na základě těchto informací snadno dohledáme problematické hodnoty, případy nebo proměnné a rozhodneme o nejvhodnějším způsobu řešení daného problému.
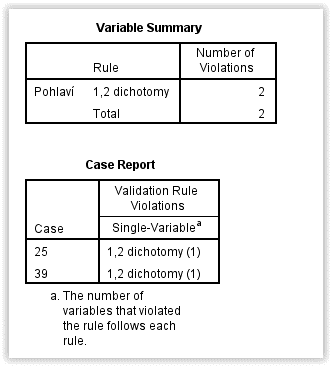
Následující obrázek zobrazuje krátkou ukázku výstupu pro situaci, kdy u proměnné Pohlaví proběhla kontrola pravidla s názvem „1,2 dichotomy“, které ověřuje, zda se v datech vyskytují pouze hodnoty 1 nebo 2. Ukazuje se, že toto pravidlo je dvakrát porušeno, a to u případů s pořadovým číslem 25 a 39.
Chcete-li se dozvědět více o postupech vedoucích k určení velikosti výzkumných souborů, přihlaste se na kurz, Stanovení velikosti výzkumného souboru, kde vás seznámíme s postupy pro vybírání výzkumných jednotek a s postupy sloužící k určení velikosti výběru.

