Chybějící hodnoty v IBM SPSS Statistics

IBM SPSS Statistics rozlišuje dva typy vynechaných hodnot (missing values): systémové (system missing) a uživatelem definované (user missing). Systémové vynechané hodnoty jsou u numerických proměnných reprezentovány prázdnou buňkou datové matice, v níž se zobrazuje symbolická tečka. Vynechané hodnoty textových proměnných (prázdné řetězce) jsou zpravidla brány jako platné, není-li nastaveno jinak. Uživatelem definované vynechané hodnoty jsou číselné (resp. textové) hodnoty, které reprezentují odpovědi typu nevím, neodpověděl, nemohu posoudit atd. Takovým odpovědím přiřazujeme určité kódy (např. 98, 99 nebo -1, -2, -3 apod.) – příslušné buňky datové matice tedy nejsou prázdné. Zvolit lze libovolné kódy dle uvážení nebo oborové konvence. Nastavení provádíme v datové matici IBM SPSS Statistics, na záložce Variable View, v poli Missing. Takto lze určit až 3 odlišné kódy, např. -1, -2, -3, nebo rozmezí hodnot a případně další diskrétní hodnotu mimo toto rozmezí, např. od -3 do -1 a 99 (viz obrázek níže).
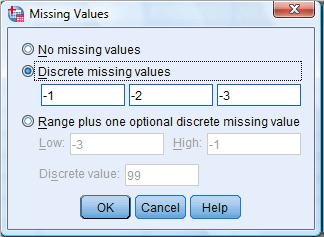
V případě, že pro analýzu potřebujeme získat úplnou datovou matici (bez systémových a uživatelem definovaných vynechaných hodnot), pak můžeme případy s vynechanými hodnotami buď vyloučit z výpočtu, nebo vynechané hodnoty imputovat, tj. nahradit.
Způsoby vyloučení případů s vynechanými hodnotami
IBM SPSS Statistics umožňuje vyřadit případ s vynechanou hodnotou pouze z výpočtu týkajícího se přímo proměnné, v níž je vynechaná hodnota (pairwise), nebo vyřadit případ s vynechanou hodnotou ze všech aktuálně prováděných výpočtů (listwise). První přístup využije maximum informace obsažené v datech, ale datová základna pro výpočet není jednotná. Druhý způsob zaručí, že výpočet bude založen na stejných případech, na druhou stranu vyloučí větší počet případů, čímž se může ztratit nemalá část informace obsažená v datech.
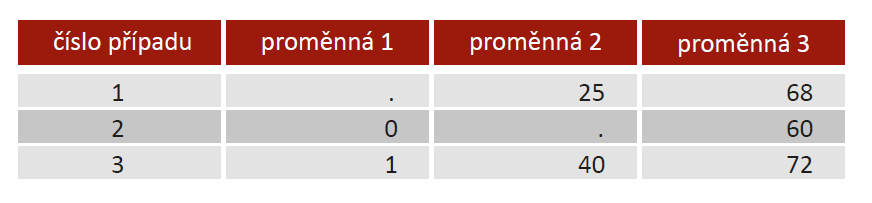
Příklad: uvažuje 3 případy, kde u prvního z nich chybí pozorování u proměnné 1, u druhého z nich u proměnné 2 a třetí případ je úplný (viz tabulka níže). Pokud bychom počítali například korelace zmíněných tří proměnných, pak použitím pairwise způsobu vyloučení případů bude korelační koeficient pro první dvě proměnné založen pouze na 3. případě, korelační koeficient pro 2. a 3. proměnnou na případech 1 a 3 a korelační koeficient pro 1. a 3. proměnnou na případech 2 a 3. Použitím listwise přístupu by případy 1 a 2 nevstupovaly do výpočtu ani jednoho ze tří koeficientů.
Vynechané hodnoty lze imputovat různými způsoby. Mezi nejjednodušší a často používané patří imputace průměrem dané proměnné. V IBM SPSS Statistics Base lze imputaci průměrem provést snadno pomocí procedury Replace Missing Values (Transform – Replace Missing Values). Tato procedura nabízí i další metody imputace na základě hodnot dané proměnné.
Sofistikovanější metody založené na modelování proměnné, jejíž hodnoty je potřeba imputovat, na základě dalších proměnných souboru, nabízí specializovaný modul IBM SPSS Missing Values. Ten zahrnuje i mnohonásobnou imputaci a analýzu struktury výskytu vynechaných hodnot.
Rádi byste se o statistice a analýze dat dozvěděli více? Chcete se stát mistrem ve svém oboru nebo si jen potřebujete doplnit znalosti? V ACREA nabízíme širokou nabídku kurzů pro váš profesní růst. Máte-li jiný dotaz. Nebojte se využít naši nezávaznou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení.

