Volební dozvuky aneb jedna zajímavost

Dostala se mi do ruky agregovaná volební data. Jednalo se o průměrný volební zisk jednotlivých parlamentních stran na úrovni okresů. Shodou okolností jsem měl k dispozici data ve stejném rozsahu a formátu i pro volby do poslanecké sněmovny za rok 2013. Řekl jsem si, jestli bych v datech neobjevil něco zajímavého, ideálně něco neznámého. Soustředil jsem se pouze na strany ČSSD a ANO, protože jejich propad, respektive vzestup byly asi nejviditelnějšími aspekty těchto voleb. Nejprve jsem začal hledat nějakou závislost mezi aktuálními výsledky ČSSD a ANO a zobrazil jsem si je do grafu. Barevně jsem odlišil české (modrá barva) a moravské (zelená barva) okresy.
Bohužel jsem dostal nic neříkající chuchvalec bodů bez nějaké zjevné závislosti, což jsem si i ověřil dalšími testy. Pořád jsem si však říkal, že nějaký vztah mezi výsledky ČSSD a ANO být musí. Vytvořil jsem tedy novou proměnnou diferencí mezi výsledky jednotlivých stran za roky 2013 a 2017 a do stejného grafu nechal zobrazit tyto rozdíly. Barevně opět odlišeny Čechy (modře) a Morava (zeleně).
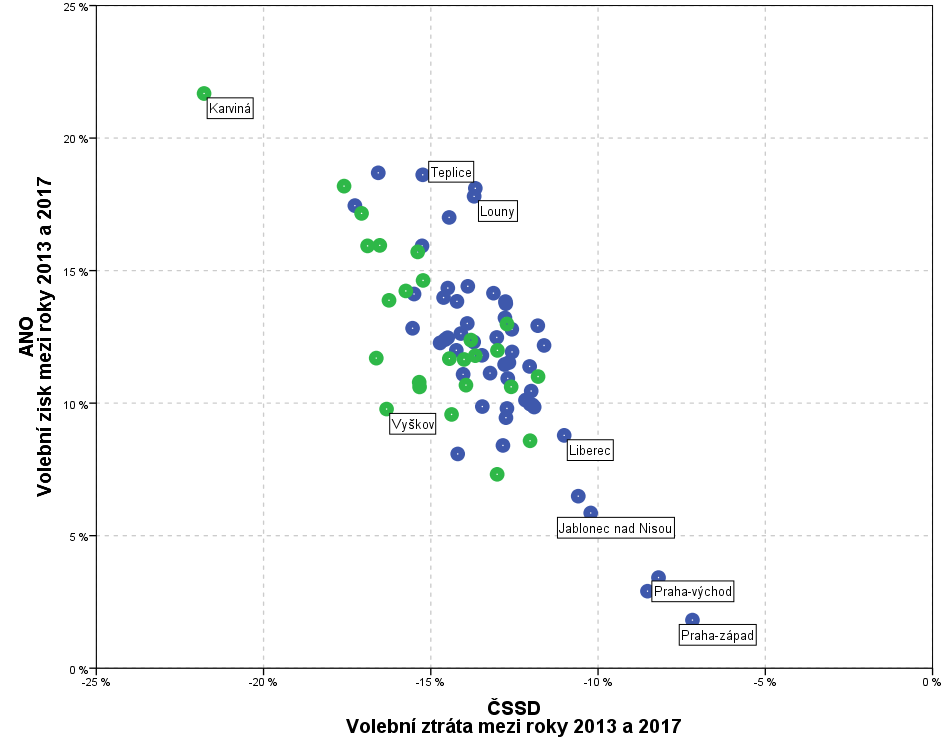
A jistá závislost se zobrazila na první pohled. Nyní tedy bylo potřeba ještě vizuálně zjištěnou závislost formalizovat a kvantifikovat. K tomu se nabízelo využít lineární regresi, protože vztah těchto dvou číselných proměnných byl na první pohled lineární.
Jako závislou proměnnou jsem zvolil rozdíl výsledků ČSSD a jako vysvětlovanou rozdíl ANO. Vyšel jsem z předpokladu, že hybatelem změn byla spíše strana ANO. Regresní analýzou jsem si potvrdil statistickou významnost vztahu těchto proměnných. Síla vztahu byla vyjádřena korelačním koeficientem 0,781. Podíl variability diferencí ČSSD (koeficient determinace) vysvětlené hodnotami diferencí ANO byl 61%. Jinak řečeno necelých 40% variability ovlivňovaly jiné vlivy, které nebyly zahrnuty v regresním modelu, pravděpodobně lokální faktory v daném okresu a zisky ostatních parlamentních stran.
Rádi byste se o statistice a analýze dat dozvěděli více? Chcete se stát mistrem ve svém oboru nebo si jen potřebujete doplnit znalosti? V ACREA nabízíme širokou nabídku kurzů pro váš profesní růst. Máte-li jiný dotaz. Nebojte se využít naši nezávaznou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení.


Ahoj Libore,
ten příklad se Ti povedl. Ale hned mě napadají další otázky a následná zkoumání:
– Jak vychází regresní koeficient? Je signifikantně odlišný od -1? Pokud ano, jakou to má interpretaci?
– Z grafu to vypadá, že regresní přímka nebude procházet počátkem souřadnic. Co nám to říká?
– Jak by dopadl regresní model se zahrnutím Čech a Moravy? Liší se model v těchto oblastech?
Ondro,
oceňuji, že se Ti příspěvek líbil a že způsobil, co způsobit měl – vyvolat další otázky!
Pokud by Tě to, nebo kohokoli jiného, zajímalo, můžeme se tomu věnovat na některém kurzu Centra výuky – přijď se podívat a dozvědět se více
Libor