Procedury pro přípravu dat: identifikace neobvyklých případů

V dalším článku ze série o procedurách pro přípravu dat v IBM SPSS Statistics si ukážeme, jak identifikovat neobvyklé případy v datech na základě jejich mnohorozměrného profilu. Důvodem pro vyhledávání neobvyklých případů je nejčastěji snaha nalézt chybné, podezřelé nebo problematické případy, které by mohly zkreslovat výsledky analýz. V některých typech úloh se však může naopak jednat o obzvlášť zajímavé případy, například o VIP zákazníky v marketingu nebo o potenciální podvodné případy při detekci podvodů.
K čemu je užitečná procedura Identify Unusual Cases
Pokud sledujeme pouze jednu číselnou proměnnou, odlehlé nebo extrémní hodnoty snadno odhalíme pomocí boxplotu, histogramu a případně různých charakteristik rozložení proměnné. U kategorizovaných proměnných může být užitečné zaměřit se na případy z řídce zastoupených kategorií.
Pokud však sledujeme více proměnných současně a zajímají nás atypické případy s ohledem na jejich mnohorozměrný profil, je již situace složitější. K tomuto účelu je určená procedura, kterou naleznete pod nabídkou Data, Identify Unusual Cases. Umožňuje identifikovat neobvyklé případy na základě seskupení případů do klastrů a jejich vzdálenosti ke středu nejbližšího klastru. Algoritmus přitom využívá metodu TwoStep Cluster. Vstupní proměnné mohou být číselné i kategorizované, předpokládá se však vzájemná nezávislost proměnných, u číselných proměnných normální rozdělení a u kategorizovaných multinomické. Procedura je ale poměrně dost robustní vzhledem k porušení těchto předpokladů.
Způsob zadávání
Na záložce Variables zadáme do pole Analysis Variables vstupní proměnné, na základě nichž budou identifikovány neobvyklé případy, a do pole Case Identifier Variables proměnnou identifikujících případy.
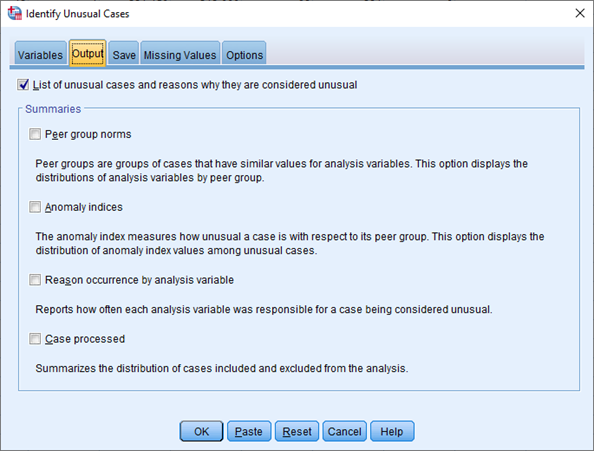
Záložka Output slouží ke specifikaci požadovaných výstupů.
Při zaškrtnutí políčka List of unusual cases and reasons why they are considered unusual se zobrazí přehled anomálních případů a informace o tom, proč jsou tyto případy považované za anomální.
V části Summaries lze volit následující výstupy:
- Peer group norms – informace o klastrech (průměr a směrodatná odchylka číselných proměnných, modální kategorie a její absolutní i relativní četnost pro kategorizované proměnné),
- Anomaly indices – popisné statistiky indexu anomality pro případy považované za anomální,
- Reason occurrence by analysis variable – přehled kolikrát byly jednotlivé proměnné označené jako hlavní důvod anomality případu a statistiky míry jejich vlivu,
- Cases processed – počty a procenta případů zahrnutých do jednotlivých klastrů a vyloučených případů.
Na záložce Save v části Save Variables volíme informace, které mají být uloženy do datové matice jako nové proměnné:
- Anomaly index – index anomality jednotlivých případů vzhledem k nejbližšímu klastru,
- Peer groups – identifikace přiřazeného klastru, absolutní a relativní velikost klastru,
- Reasons – název proměnné, která představuje hlavní důvod anomality, hodnota této proměnné, míra jejího vlivu a norma v daném klastru (průměr nebo modální kategorie podle typu proměnné).
Dále určíme, zda mají být v případě konfliktu názvů nahrazeny dříve vytvořené proměnné (Replace existing variables that have the same name or root name).
V části Export Model File lze uložit model do formátu XML.
Na záložce Missing Values volíme způsob práce s vynechanými hodnotami:
- Exclude missing values from analysis – případy s vynechanými hodnotami jsou vyloučené z analýzy,
- Include missing values in analysis – vynechané hodnoty spojitých proměnných jsou nahrazené průměrem proměnné, u kategorizovaných proměnných jsou považované za speciální kategorii.
Zaškrtávací políčko Use proportion of missing values per case as analysis variable umožňuje užít pro analýzu rovněž proměnnou, které vyjadřuje podíl vynechaných hodnot u jednotlivých případů.
Na záložce Options v části Criteria for Identifying Unusual Cases nastavíme kritéria pro zařazení případů mezi anomální:
- Percentage of cases with highest anomaly index values – zadané procento případů s nejvyšším indexem anomality,
- Fixed number of cases with highest anomaly index values – daný počet případů s nejvyšším indexem anomality.
Při zaškrtnutí políčka Identify only cases whose anomaly index value meets or exceeds a minimum value můžeme navíc přidat omezení, že index anomality musí být vyšší než zadaná hodnota.
V části Number of Peer Groups nastavíme minimální a maximální hodnotu pro počet klastrů.
V poli Maximum Number of Reasons nastavíme maximální počet proměnných, které budou uvedeny jako hlavní důvod anomality.
Výstupy
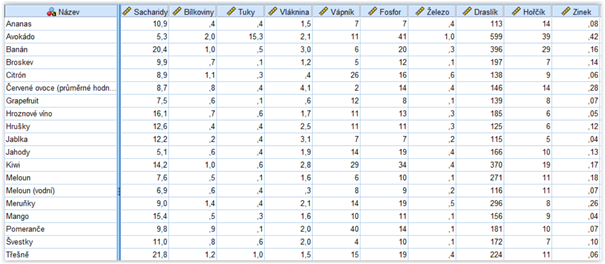
Vyhledávání neobvyklých případů si ukážeme na jednoduchém příkladě. Datový soubor (viz obrázek níže) obsahuje informace o nutričních hodnotách 19 druhů ovoce: podíl sacharidů, bílkovin, tuků a vlákniny (v gramech na 100 gramů ovoce) a dále množství vybraných minerálů (v mg na 100 gramů ovoce). Na řádku označeném „Červené ovoce“ jsou uvedené průměrné hodnoty pro borůvky, maliny a ostružiny. Pomocí procedury Identify Unusual Cases se pokusíme zjistit, zda se mezi uvedenými druhy nevyskytují takové, které by se svým složením výrazně odlišovali od ostatních.
Procedury Identify Unusual Cases automaticky provede standardizaci proměnných, proto nevadí, že jsou vyjádřené v různých jednotkách.
V dialogovém okně na záložce Variables zadáme do pole Analysis Variables všechny proměnné udávající nutriční hodnoty a do pole Case Identifier Variable název ovoce. Na záložce Output necháme označené pouze základní výstupy. Na záložce Options upravíme nastavení v části Number of Peer Groups: Minimum=1, Maximum=1 tak, aby se vytvořil pouze jeden klastr. Dále zvýšíme hodnotu v poli Maximum Number of Reasons na 3 (tj. pro každý neobvyklý případ se zobrazí tři proměnné, jejichž hodnoty nejvíc přispívají k tomu, že byl případ označený jako atypický).
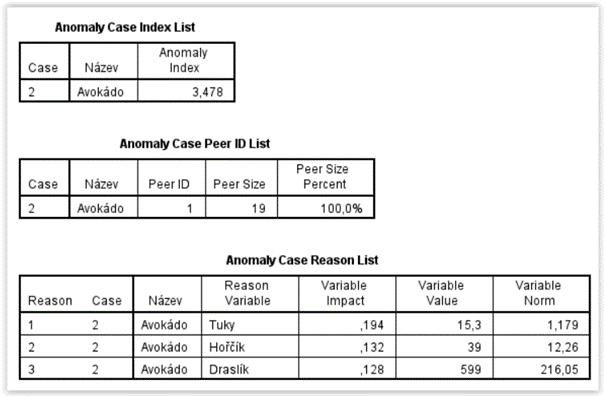
Z tabulky Anomaly Case Index List vyplývá, že byl nalezen jeden druh ovoce, který má celkově výrazně odlišné složení ve srovnání s ostatními, a tím je avokádo. Statistika Anomaly Index vyjadřuje podíl logaritmicko-věro hodnostní vzdálenosti daného případu k nejbližšímu klastru vzhledem k průměrné vzdálenosti ostatních případů z tohoto klastru k tomuto klastru. Hodnota 1 tedy charakterizuje průměrný případ z klastru a čím vyšší je toto číslo, tím více anomální je daný případ.
Tabulka Anomaly Case Peer ID List obsahuje informace o klastru, do kterého byl přiřazen tento anomální případ. V tomto případě jsme požadovali vytvoření pouze jednoho klastru, který tak obsahuje všech 19 případů (tj. 100 % případů).
Tabulka Anomaly Case Reason List zobrazuje tři hlavní důvody anomality případu. Pro lepší přehlednost je přepivotovaná tak, aby byly vidět všechny tři důvody současně. Ukazuje se, že k odlišnosti avokáda nejvíce přispívá výrazně vyšší podíl tuků 15,3 g na 100 gramů (Variable Value), zatímco u ostatních druhů ovoce je to v průměru jen 1,179 g na 100 gramů (Variable Norm). Charakteristika Variable Impact vyjadřuje proporcionální příspěvek této proměnné k anomalitě případu. Jako další důvody jsou uvedené vyšší obsah hořčíku a draslíku.
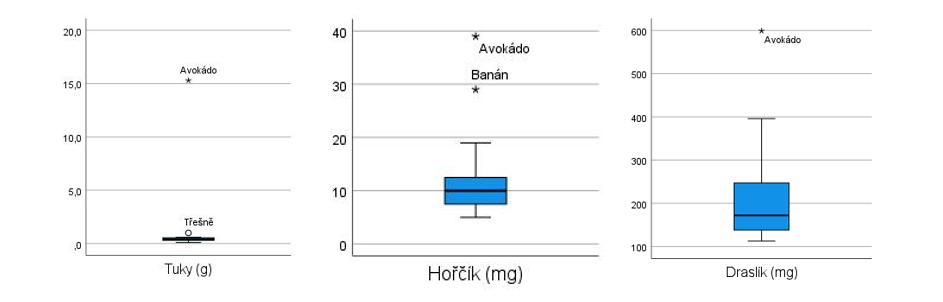
Rozložení těchto tří proměnných můžeme znázornit graficky pomocí boxplotu (vzhledem k odlišným jednotkám vytvoříme pro každou z nich samostatný graf). Z obrázků je vidět, že u všech tří proměnných představuje avokádo extrémní hodnotu.


Dobrý den,
předpokládám správně, že procedura „Identify Unusual Cases“ je dostupná až ve vyšší verzi sw IBM SPSS? Já mám instalovanou verzi 23.
Děkuji za odpověď.
Dobrý den,
procedura „Identify Unusual Cases“ byla ve starších verzích IBM SPSS Statistics zařazená do modulu „Data Preparation“ (abyste s ní mohla pracovat, bylo nutné mít tento modul). Ve verzi 27 je ale nově zařazená do základního modulu Base.