Nenechte své zákazníky odejít (Churn analýza)

Jednou z nejstarších komerčních úloh datové vědy je optimalizace retenčních kampaní. V konkurenčním tržním prostředí se vyplatí investovat do udržování vlastních zákazníků více než se snažit přetahovat nové zákazníky od konkurence. Úloze se slangově říká churn a spočívá v přípravě klasifikačního modelu, který dokáže u každého zákazníka rozpoznat, zda v blízké budoucnosti hodlá změnit poskytovatele služeb, nakupovat v jiném obchodě nebo přejít k druhému dodavateli. Pro udržení stávajících zákazníků dodavatelé chystají retenční kampaně, do nich jsou nominováni zákazníci na základě předpovědí klasifikačního modelu. V rámci kampaně vybraní zákazníci obdrží nějakou výhodnou nabídku, která by měla zvrátit jejich sklony k odchodu ke konkurenci. Úkolem datového vědce nebývá jen vytvoření predikčního modelu, ale i vyhodnocení přínosů retenčních kampaní využívajících model.
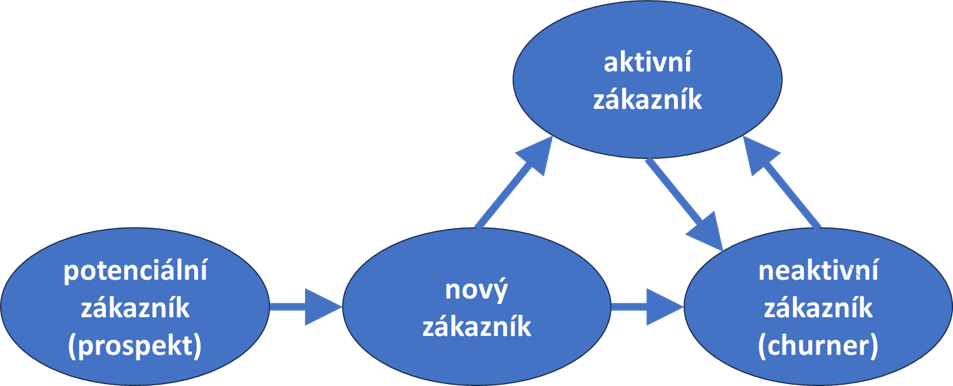
Jak se to celé dělá si ukážeme na příkladu e-shopu na prodej mobilních telefonů. E-shop vznikl v lednu 2023 a už od počátku nabízí zákazníkům různé slevy. Protože prodej mobilních telefonů po Vánocích vždy strmě klesne, e-shop zveřejňuje začátkem roku slevové kódy v tisku, na sociálních sítích a v internetové reklamě. To mimo jiné napomáhá i při akvizici nových zákazníků. Stávající zákazníky zase udržuje tak, že pořádá slosování objednávek. Výhercům zasílá slevový kód e-mailem. Oba dva typy kampaní jsou však plošné, necílí na zákazníky se sklony k odchodu.
Od poloviny roku 2024 se e-shop rozhodl rozšířit a zacílit své marketingové aktivity. V reklamě na získávání nových zákazníků se zaměřil na nejprofitabilnější segmenty, zavedl pravidelné měsíční retenční kampaně, do nichž nominuje zákazníky klasifikační model, a implementoval doporučovací systém, který při návštěvě e-shopu nabízí mobilní telefony na základě preferenčního modelu. My si popíšeme pouze retenční kampaně.
Úkolem klasifikačního modelu je rozpoznat stávají zákazníky, kteří se stanou neaktivními. Při definici neaktivity předpovídané modelem, jsme vycházeli z RFM analýzy provedené za účelem zacílení akvizičních reklam. Při RFM analýze pro každého zákazníka spočteme tří číselná skóre:
- R (recency) vyjadřuje počet dní od posledního nákupu,
- F (frequency) udává kolik nákupů už zákazník provedl,
- M (monetary) představuje celkovou zaplacenou sumu.
Po diskusi a několika jednoduchých analýzách se obchod rozhodl, že za neaktivního zákazníka bude považovat toho, kdo si nic neobjednal během posledních dvanácti měsíců (recency). Do kategorie aktivních zákazníků se zařadí ten, kdo během posledního roku učinil alespoň tři objednávky (frequency). Data o aktivních a neaktivních zákaznících se použila na strojové učení klasifikačního modelu. Zákazníci nespadající ani do jedné skupiny učení klasifikátoru neovlivnili, neboť jejich chování není vyhraněné.
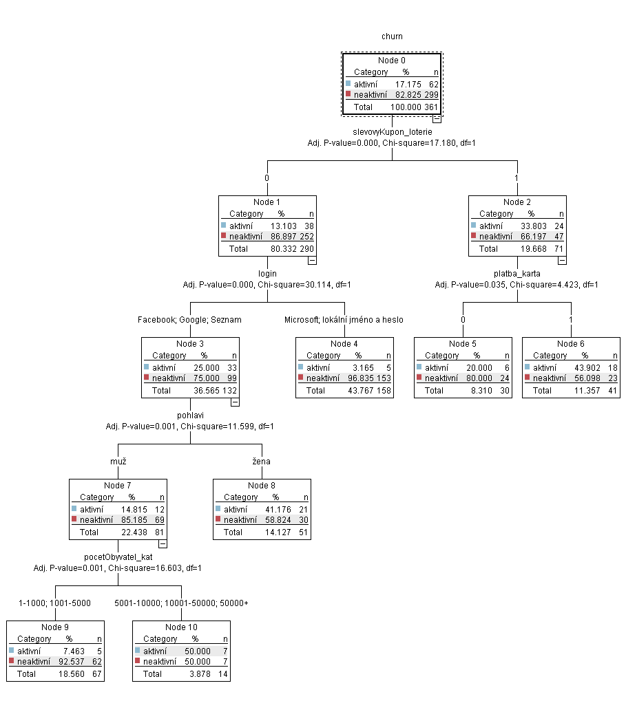
V modelovací matici složené z aktivních a neaktivních zákazníků jsou jednak vstupní proměnné a jednak příznak neaktivity v roli výstupní proměnné. Vstupní proměnné lze rozdělit na statické a behaviorální. Statické odráží neměnné vlastnosti zákazníků odvozené z údajů, které zákazníci vkládají při registraci do e-shopu. Z křestního jména můžeme usuzovat na pohlaví, z doručovací adresy odvodíme region a velikost sídla. Mezi statické proměnné lze též zařadit způsob přihlašování, neboť zákazníci se mohou do obchodu hlásit nejen jménem a heslem, ale i skrze jiné účty jako třeba Google nebo Facebook. Behaviorální vstupní proměnné naopak reflektují nákupní chování zákazníků. Patří mezi ně preferovaný způsob platby (dobírka, karta, rychlý bankovní převod, elektronická peněženka, …), značky dříve zakoupených telefonů nebo uplatňování slevových kódů.
Při sestavování modelovací matice je třeba zohlednit, že predikované chování reprezentované cílovým příznakem neaktivity je definováno na základě objednávek provedených během dvanáctiměsíčního období. Při nominování zákazníků do kampaně bude model předpovídat neaktivitu zákazníků v budoucím roce na základě znalosti aktuálních vstupních proměnných. Proto při sestavování modelovací matice určené k učení klasifikačního modelu bylo nutné provést posunutí vstupních proměnných o dvanáct měsíců zpět do historie, abychom simulovali situaci, která nastane při používání modelu. Například, když sestavujeme modelovací data k 1.7.2024, jsme schopni do datové matice jako výstupní proměnnou zaznamenat roční neaktivitu zákazníků od 1.7.2023. A k tomuto datu musíme vztáhnout i vstupní proměnné.

Další kroky již představují pro datového vědce rutinu. Záznamy v modelovací matici byly rozděleny do tréninkové a testovací množiny. Nad tréninkovou množinou probíhalo strojové učení klasifikačního modelu, zatímco testovací množina sloužila k nezávislému posouzení kvality klasifikátoru. Během učení se zkoušely různé klasifikační algoritmy a nastavovaly jejich metaparametry. Jako nevhodnější kandidát byl nakonec vybrán rozhodovací strom vytvořený algoritmem CaRT a to především díky své transparentnosti. Interpretace postupu rozhodování stromem byla ve shodě s tím, jak vnímají chování zákazníků marketingoví analytici. Na základě odhadu kvality a přínosů klasifikačního stromu na testovací množině se e-shop rozhodl, že model pro nominaci zákazníků do plánovaných retenčních kampaní použije.
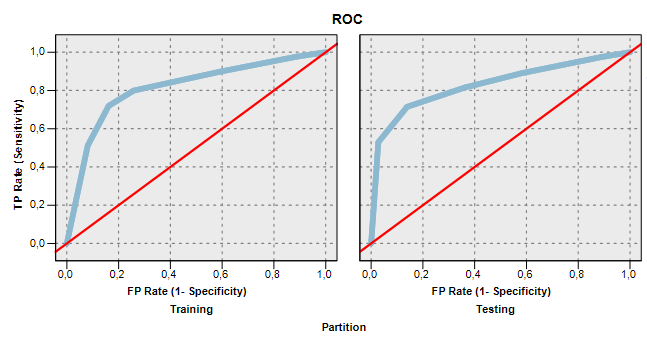
Pro odhad kvality klasifikátoru se standardně vychází z matice záměn, čtyřpolní kontingenční tabulky četností, které dává do souvislosti známé hodnoty příznaku neaktivity a její predikce. Vzhledem k tomu, že hlavním použitým výstupem modelu je skóre, je vhodné posoudit kvalitu modelu na základě vztahu skóre a známého příznaku neaktivity. Číselné skóre by mělo být úměrné pravděpodobnosti neaktivity. Při nominaci do kampaně se zákazníci seřadí podle skóre a do kampaně se vybere stanovený počet zákazníků s nejvyšším skóre. Kvalitu klasifikačního modelu jsme proto posuzovali pomocí ROC křivky a s ní spojené Giniho statistiky. Giniho statistika nabývá hodnot v rozsahu od nuly do jedné. Nula odpovídá modelu, co vybírá zákazníky do kampaně zcela náhodně, jednotkovou hodnotu statistiky by získal model, který každému skutečně neaktivnímu zákazníkovi přiřadí vyšší skóre než jakémukoli aktivnímu.
Kvalitu klasifikátoru bychom měli též hodnotit z hlediska jeho finančních přínosů porovnáním nákladů a výnosů. Do nákladů můžeme započítat i fixní investici do vývoje modelu a provozní náklady na jeho udržování a monitorování. Hlavní náklad však tvoří nabídka slevy. Pokud nabídneme slevu zákazníkovi, který by si i bez nabídky koupil mobilní telefon, náklad byl vynaložen zbytečně, e-shop přišel o marži odpovídající slevě. Pokud nabídneme slevu tomu, kdo nákup stejně neprovede, nejde ani o zisk ani o ztrátu. Pokud nabídneme slevu zákazníkovi, který by si nic nekoupil, ale díky slevě se rozhodl pro koupi nového telefonu, jedná se o zisk odpovídající marži po slevě. Vyčíslení výnosů je problematické, neboť v případě, že zákazníkovi slevu nabídneme, nedovíme se, zda by si nějaký telefon koupil i bez slevy. Naopak pokud někomu slevu nenabídneme a on si nic nekoupí, nevíme, k jakému nákupu by došlo, kdyby slevu měl. Výnosy tak můžeme pouze hrubě odhadnout, když například budeme předpokládat, že sleva zapůsobí zhruba na stejné procento zákazníků jako sleva nabídnutá při slosování objednávek a že si zákazník při uplatňování slevového kódu objedná průměrný telefon. Tímto hrubým odhadem můžeme vyčíslit jak absolutní zisk v Kč, tak relativní zisk v procentech na vynaloženou korunu (Return On Investment, ROI) v závislosti na počtu oslovených zákazníků.
Podívejte se na webinář:
Využití AI a machine learningu pro prevenci odlivu zákazníků
Ukážeme vám, jak na analýzu dat krok za krokem.

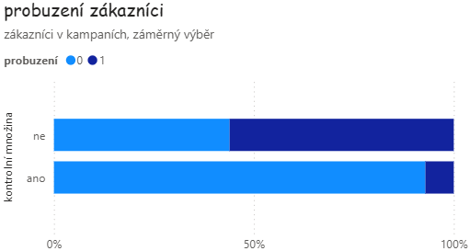
Praktické používání klasifikačního modelu je úzce spjato s plánováním retenčních kampaní. Při plánování kampaní je potřeba pamatovat na to, že budeme přínosy modelu monitorovat a sledovat, jak dobře rozpoznává neaktivní zákazníky. Do každé kampaně e-shop nominuje i náhodně vybrané zákazníky, abychom porovnali, o kolik je záměrný výběr provedený klasifikačním modelem lepší než výběr náhodný. Dále se ze všech vybraných zákazníků vyčleňuje kontrolní množina. Zákazníkům z kontrolní množiny se žádná nabídka nezasílá. Díky kontrolní množině může e-shop nejen vyhodnotit, jak nabídnutá sleva přesvědčí zákazníka k novému nákupu, ale především umožní kontrolovat přesnost rozpoznávání budoucí neaktivity. Kdybychom neměli kontrolní množinu a oslovovali všechny vybrané zákazníky, mnozí neaktivní by se díky nabídnuté slevě stali aktivními. To je sice primárním cílem retenčních kampaní, ale brání to korektnímu hodnocení kvality nasazeného modelu.
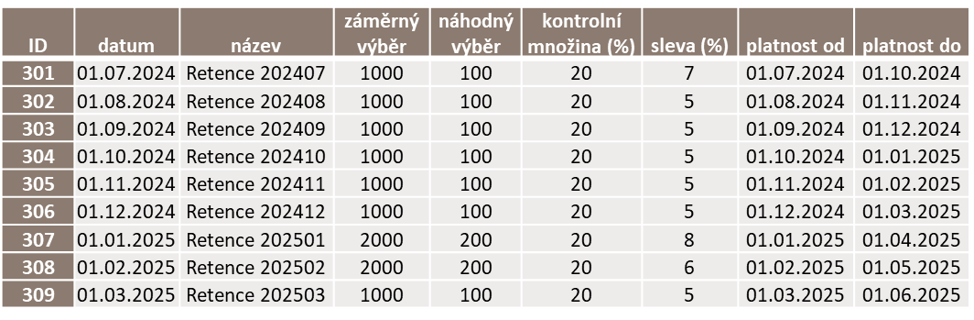
Při plánování retenčních kampaní e-shop také dodržuje pravidla na kontaktování zákazníků, aby nebyli zahlceni množstvím zpráv a nabídek. Neoslovují se zákazníci, kteří byli nominováni do jakékoli cílené kampaně během posledních tří měsíců. A také se neoslovují ti, kteří během posledních tří měsíců využili slevový kód z nějaké plošné kampaně. Protože klasifikátor umožnuje řazení zákazníků podle skóre za každého zákazníka vyloučeného z retenční kampaně z výše uvedených důvodů snadno najdeme náhradníka a naplníme plánovanou kvótu pro kampaň.
Díky přidání náhodně vybraných zákazníků do kampaní, a především díky kontrolní množině můžeme monitorovat přínosy klasifikačního modelu pomocí mnoha statistik. Pro rychlé manažerské zhodnocení je vhodné uvést, o kolik procent klesá podíl neaktivních zákazníků díky retenčním kampaním a jaká je návratnost investice (ROI) spočívající v cílené nabídce slevy. V podrobnějším reportu jsou pak analyzovány podíly akceptace nabídnuté slevy a podíly probuzených neaktivních zákazníků porovnávané s kontrolní množinou. Internetový obchod sleduje měsíční časové řady těchto ukazatelů a analyzuje je ve vztahu ke statickým i behaviorálním atributům zákazníků. Samozřejmostí je i průběžné sledování kvality modelu pomocí Giniho statistiky použité při evaluaci. Díky zavedení kontrolní množiny, může korektně posoudit, zda vybraní zákazníci s vysokým skóre byli v následujících dvanácti měsících skutečně neaktivní.
Na závěr ještě zmíníme, jaké technologie a nástroje byly použity. E-shop nemá žádný speciální software pro vývoj predikčních modelů. Dokáže však spouštět podle potřeby programy napsané v Pythonu. Hodně též využívá softwary od Microsoftu. Marketingoví analytici používají převážně Excel, mnoho reportů je dnes už převedeno do Microsoft Power BI a k provádění opakovaných úloh se používá MS Power Automate.
V oblasti datové vědy je dnes zřejmě nejrozšířenější Python a jeho speciální balíčky. Pro přípravu dat, strojové učení a evaluaci klasifikačního modelu byl však použit software SPSS Modeler, jenž nabízí na rozdíl od Pythonu přehledné grafické rozraní. Výsledné postupy se ale nakonec přepsaly do Pythonu, a e-shop spouští skripty pro nominaci a vyhodnocení kampaní v MS Power Automate. Monitorovací reporty jsou implementovány v MS Power BI. Celý proces nominace a vyhodnocení je automatizován, marketingoví analytici dostávají pravidelné reporty. Jednou přibližně za půl roku musí připravit plán dalších kampaní a průběžně kontrolují, zda klasifikační model má stále dostatečnou přesnost.
Chcete se na svá zákaznická data podívat z nové perspektivy?
Potřebujete pomoci s Churn analýzou?
Využijte krátkou 30 minutovou konzultaci s našimi specialisty.
REZERVUJTE SI TERMÍN JEŠTĚ DNES!
