Jednoduchá předpověď vývoje počtu nakažených a mrtvých

Sledujeme-li vývoj počtu nakažených a mrtvých během druhé vlny koronavirové epidemie, snadno zjistíme, že když pomineme pravidelné týdenní oscilace, počty rostou čím dál rychleji[1]. Ovlivnila vývoj epidemiologická opatření? Kdy a na jaké hodnotě se počty nakažených a mrtvých zastaví?
Budeme-li počty v druhé vlně analyzovat jako časovou řadu, snadno zjistíme, že samotné počty nenaznačují, že by epidemiologická opatření na jejich vývoj měla nějaký vliv. Časové řady geometricky rostou. To znamená, že i rychlost růstu se stále zvětšuje. Jednoduchou extrapolací pak můžeme odhadnout, kdy budeme pozitivní všichni.
Prezentovaný model je samozřejmě dosti naivní a nemůže konkurovat epidemiologickým modelům simulujícím šíření nákazy v populaci. Nutno však dodat, že tento jednoduchý model dobře předpovídá počty nakažených a mrtvých od začátku druhé vlny doposud1. Domnívám se, že odchylky od geometrického růstu se již brzy projeví, už jen proto, že v ČR žije 10 milionů obyvatel a víc nás tu být pozitivních nemůže. Pojďme se ale na model časové řady podívat detailněji a komentovat jeho paradoxní predikce.
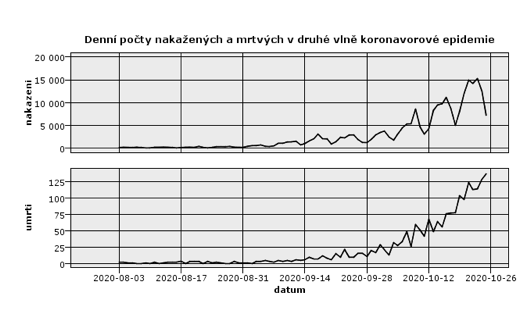
Obrázek ukazuje denní počty nakažených a mrtvých. Nejedná se kumulativní počty často prezentované v médiích, ale o denní přírůstky. Jistě si všimnete týdenní sezónnosti počtu nakažených. Přes víkend se testuje méně, a proto je počet prokázaných případů nižší.
Protože nám nepůjde o detailní predikci denního vývoje, ale o odhad dlouhodobějšího trendu, denní časové řady agregujeme na týdenní. Zbavíme se tak týdenních oscilací, což výrazně zjednoduší model. Týdenní řady však stále nabídnou dostatečný detail pro zachycení vlivu epidemiologických opatření.
[1]situace k 25.10. 2020
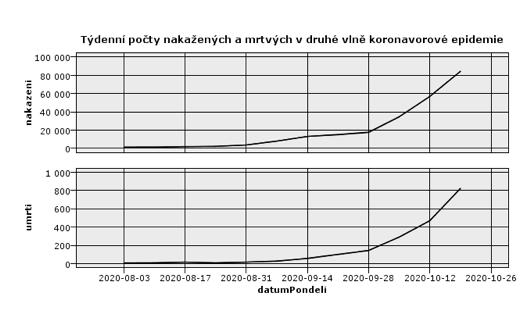
Na týdenních řadách z obrázku není vidět jasná změna trendu po zavedení některého z balíčků opatření. Pro další zjednodušení analýzy a predikce ještě řady logaritmujeme. Pokud je nárůst počtů skutečně geometrický, logaritmované řady budou lineární, v grafu logaritmované řady uvidíme rostoucí přímku.
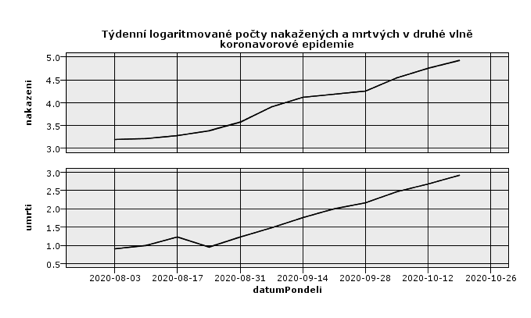
Na obrázku vidíme, že logaritmované řady jsou skutečně lineární. Opět tu není žádná stopa po epidemiologických opatřeních. Pokud bychom opatření zkusili do modelu přidat jako vysvětlující vlivy ve formě tzv. schodových indikátorových událostí, také bychom zjistili, že jsou nesignifikantní a do modelu je nemá smysl přidávat.
Jediný vysvětlující vliv, který se modelováním podařilo prokázat, je testování. Počet provedených testů se ukázal jako velmi silný prediktor počtu nakažených. Čím více testů, tím více nakažených. Takovou interpretací však zjevně porušujeme kauzalitu, proto z modelu testování také vyloučíme.
Další vysvětlující faktory v datové sadě nemáme, a proto predikce opřeme pouze o historii časových řad. Logaritmované řady mají poměrně neměnný lineární (původně geometrický) nárůst, jakýkoli rozumný model bude předpovídat jeho pokračování. Sklon predikované přímky jen mírně ovlivní počet historických týdnů, které k odhadu použijeme. Zřejmě má smysl se zabývat pouze druhou vlnou epidemie, proto si při odhadování vystačíme s daty od počátku srpna.
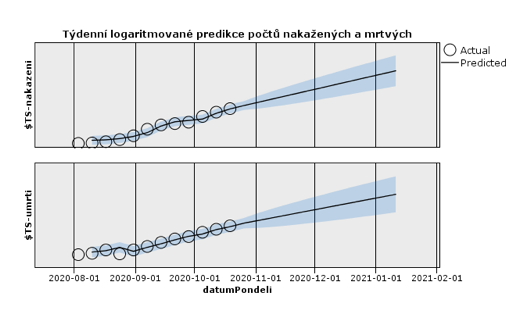
Jak by vypadaly počty nakažených a mrtvých, kdybychom se na tento jednoduchý model spolehli? Po odlogaritmování lineární predikce zjistíme například z kumulativních počtů, že do Vánoc nákazu budeme mít za sebou všichni a v ČR letos zemře v druhé vlně 200 tisíc lidí. Nemusíme se však bát, tento scénář se jistě nenaplní. Každá epidemiologická křivka se jednou ohne, nárůst se zpomalí, zastaví a zpravidla i přejde v pokles.
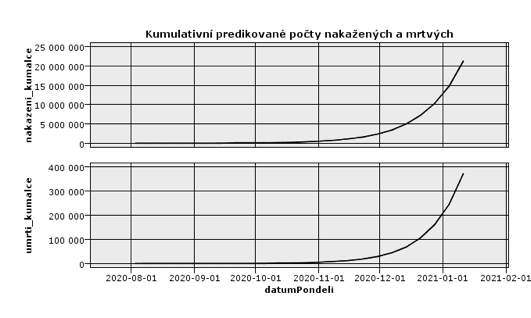
Všechny epidemie v historii lidstva odezněly, některé však zanechaly se sebou smutné následky. Možné následky koronavirové epidemie ovlivňuje smrtnost, tj. pravděpodobnost, že nakažený pacient zemře. Smrtnost koronaviru se bohužel obtížně odhaduje z hromadných dat, kde se mění tempo nových přírůstků. Odhady jsou i přesto silně nadhodnocené. Pokud nemáme reprezentativní otestovaný výběr z populace, u bezpříznakových pacientů se nedozvíme, že jsou nakaženi, a tím se zmenší jmenovatel odhadu smrtnosti. Čitatel s počtem mrtvých se však nemění, o těch informováni jsme.
Odhadů smrtnosti není mnoho. Odhadová smrtnost v ČR se stále snižuje, v současnosti se prezentují odhady do dvou procent, některé zdroje uvádí i smrtnost menší než 1 %. Osobně se domnívám, že v české populaci je několikrát více bezpříznakových a nediagnostikovaných pacientů než těch s pozitivními testy. Moji hypotézu podporuje výše popsaný jednoduchý model, protože se v něm neprojevuje vliv epidemiologických opatření. Nemoc je zkrátka už rozšířená, snažíme se zabránit útoku nepřítele, který už pronikl do opevnění.
Není však důvod k panice. Ukazuje to na mnohem nižší smrtnost. Pokud je počet bezpříznakových opravdu několikanásobkem diagnostikovaných, smrtnost by se mohla dostat až na úroveň běžných infekčních nemocí. Covid zkrátka není pro nakažené tolik nebezpečný, jak jsme se doposud domnívali. Dokáže se však šířit tak rychle, že nejsme schopni tomu zabránit. Pokud jsou mé úvahy správné, velmi brzy se změní dosavadní geometrický nárůst počtu nakažených a mrtvých. Domnívám se, že populace v ČR, čítající 10 milionů obyvatel, je tak promořená, že už není možné, aby se počet příznakových pacientů a mrtvých zvyšoval dosavadním tempem. V důsledku toho se růstové křivky v nejbližších týdnech začnou ohýbat na druhou stranu.
Rádi byste se o statistice a analýze dat dozvěděli více? Chcete se stát mistrem ve svém oboru nebo si jen potřebujete doplnit znalosti? V ACREA nabízíme širokou nabídku kurzů pro váš profesní růst. Máte-li jiný dotaz. Nebojte se využít naši nezávaznou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení.

