Využívejte Python pro rozšíření možností IBM SPSS Statistics

Program IBM SPSS Statistics je velmi silným nástrojem pro analýzu dat. Nabízí široké portfolio statistických metod i dalších funkcí pro práci s daty. Jako univerzální statistický software však nemůže zcela postihnout všechny potenciální potřeby zákazníků z mnoha různých oborů. Existují situace, kdy potřebujete rozšířit funkčnost programu o něco speciálního na mírů Vašim potřebám či zvyklostem oboru. K tomu lze využít spolupráci IBM SPSS Statistics s programovacími jazyky, především Python, R a Java. Tímto způsobem například přidáte do programu další statistické procedury, které se budou spouštět přímo z menu programu, zadávat pomocí standardních dialogů a mít vlastní syntaxový příkaz či zautomatizujete práci s výstupy. V tomto článku si přiblížíme možnosti spolupráce s Pythonem.
Python a instalace
Python je moderní, volně šiřitelný programovací jazyk, který je vyvíjen jako open-source, což znamená, že si každý může přečíst zdrojový kód. Mezi jeho výhody patří výkonnost a zároveň jednoduchá syntax – dobře se čte a dá se rychle naučit. Lze v něm vytvářet jak jednoduché programy (například skripty), tak velmi komplexní programy.
Při instalaci IBM SPSS Statistics verze 29 se standardně instaluje rovněž Python a vše potřebné pro to, aby bylo možné tuto spolupráci využívat, a to:
- Python 3.10
- Integration Plug-in for Python
- Python Extension Commands for SPSS Statistics – ukázkové procedury.
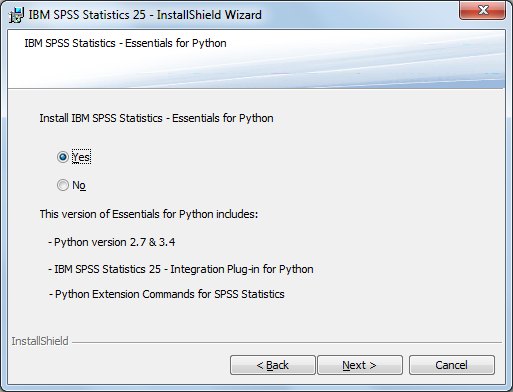
Integrační plug-in pro Python zahrnuje dvě rozhraní pro programování v Pythonu v rámci IBM SPSS Statistics:
- Python Integration Package obsahuje funkce, které umožňují přistupovat k procesoru IBM SPSS Statistics, rozšířit syntaxové příkazy s plným využitím Pythonu, přistupovat k informacím o proměnných, k jednotlivým případům i výstupům procedur. Za pomoci syntaxe IBM SPSS Statistics lze vytvářet nové proměnné či případy v aktivním datovém souboru, vytvořit nový soubor nebo vytvářet výstupy ve formě pivotních tabulek či textu.
- Scripting Facility poskytuje funkce pro práci s uživatelským rozhraním a výstupovými objekty – například pro úpravu pivotních tabulek nebo export výstupových objektů (tabulek, grafů apod.) do různých formátů.
Součástí instalace jsou rovněž ukázkové procedury vytvořené v Pythonu, které demonstrují příklady využití.
Pro uživatele starších verzí: možnost integrovat Python v rámci IBM SPSS Statistics je k dispozici od verze 14, postupně se rozvíjí, zdokonaluje a zjednodušuje. U nižších verzí než 21 je instalace o něco složitější – některé komponenty je nutné stahovat z internetu a instalaci provádět v několika krocích.
Možnosti využití integrace Pythonu
Ukázkové procedury vytvořené v Pythonu. Jsou označené modrou ikonkou s křížkem. Zadávají se standardním způsobem jako běžné procedury, součástí dialogu však bývá upozornění, že vyžadují integrační plug‑in pro Python (This dialog requires the Python plug-in).

Tyto procedury jsou nejčastěji instalovány ve formě tzv. softwarového balíčku – souboru s příponou SPE. Tyto balíčky obsahují softwarová rozšíření IBM SPSS Statistics včetně všech komponent, které jsou nutné pro jejich instalaci (například program v Pythonu včetně uživatelského dialogu a XML souboru definujícího syntaxový příkaz). Důvodem vytváření balíčků je zjednodušení instalace těchto rozšíření. Uživatelé mohou balíčky rovněž sami vytvářet a sdílet mezi sebou.
Pro správu softwarových rozšíření a připojení k portálu pro jejich sdílení mezi uživateli, je určena nabídka Extensions, Extension Hub. Aktuálně jsou k dispozici desítky až stovky takových rozšíření. Tento dialog nabízí možnost snáze se v nich orientovat, třídit je podle zaměření, stahovat, instalovat, získat přehled o požadovaném softwarovém vybavení apod.
V nabídce Extensions lze rovněž provést lokální instalaci rozšiřujícího balíčku uloženého na počítači či v rámci sítě (Install Local Extension Bundle), nebo nainstalovat či vytvořit vlastní dialog, který se stane automaticky součástí softwarového rozšíření (Custom Dialog Builder for Extensions).
Jiným příkladem využití Pythonu v IBM SPSS Statistics jsou skripty. Obvykle se jedná o soubory s koncovkou PY, které se užívají pro práci s výstupovými objekty – například pro úpravu pivotních tabulek. Uživatelé si mohou vytvářet vlastní skripty a sdílet je mezi sebou nebo přebírat již vytvořené. Společnost ACREA CR nabízí svým zákazníkům řadu skriptů zdarma ke stažení.
Některé skripty vyžadují, aby byl před jejich spuštěním označen upravovaný objekt určitého typu (například skript pro výpočet intervalů spolehlivosti v tabulce četností vyžaduje, aby byla v aktivním výstupovém okně označena tabulka četností). Tyto požadavky by měly být podrobně popsány v dokumentaci skriptu. Skript spustíme pomocí nabídky
Utilities, Run Script nebo kliknutím na ikonu Run Script. ![]()
Pro jednotlivé skripty lze však také vytvořit vlastní ikony, přidat je na nástrojovou lištu a nastavit propojení se skriptem tak, aby se při kliknutí na ni automaticky spustil. Součástí skriptu může být rovněž dialog pro specifikaci zadání.
Oba přístupy lze samozřejmě také kombinovat nejen mezi sebou, ale i s dalšími postupy automatizace (například se syntaxí).
Příklad 1 – užití ukázkové procedury SPSSINC_RAKE pro vyvážení dat
V řadě situací je třeba datový soubor vyvážit tak, aby měl požadovanou strukturu. Například při analýze dat z výběrových šetření je nutné zajistit reprezentativnost souboru pomocí designových a/nebo poststratifikačních vah. Poststratifikační váhy se konstruují až po sběru dat v případě, že struktura souboru váženého designovými vahami neodpovídá struktuře celé populace. Jejich cílem je alespoň částečně tuto situaci napravit vyvážením dat podle několika zvolených základních znaků. Konstrukce poststratifikačních vah bývá poměrně náročnou záležitostí. Jedním z možných postupů je tzv. raking s využitím procedury GENLOG, která je součástí modulu IBM SPSS Advanced Statistics.
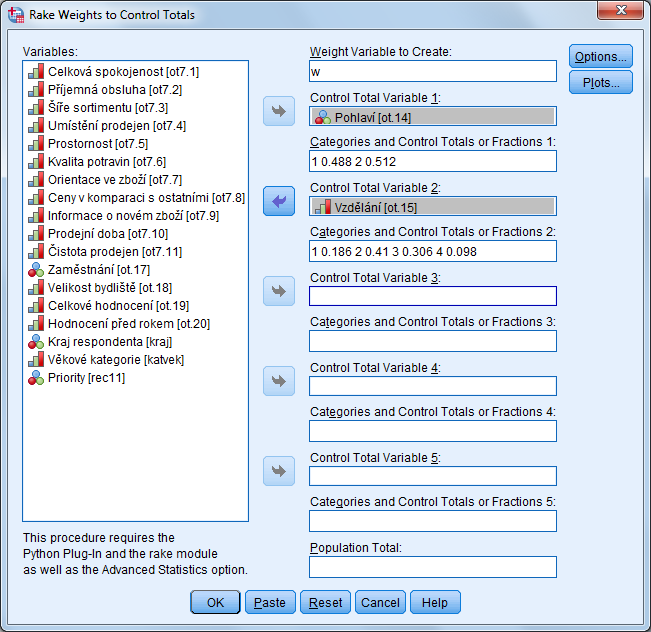
Ukázková procedura SPSSINC_RAKE tento postup provede a datový soubor vyváží na základě zadaných proměnných a požadovaných marginálních proporcí. Pokud jsou data již vážená například designovými vahami, vychází výpočet z počátečních vah. Procedura vyžaduje kromě integrace Pythonu také modul IBM SPSS Advanced Statistics.
Proceduru spustíte z nabídky Data, Rake Weights. V dialogovém okně zadáte do pole Weight Variable to Create název nové proměnné, která bude vyjadřovat váhu a v polích Control Total Variable 1 … 5 specifikujete až pět numerických kategorizovaných proměnných, na základě nichž se soubor vyváží. Pro zadání více proměnných (maximálně 10) lze užít syntax, je však třeba si uvědomit, že s větším počtem proměnných narůstá také riziko velkého rozptylu vah a výskytu extrémních hodnot.
V polích Categories and Control Totals or Fractions 1 … 5 zadáte pro jednotlivé proměnné požadované marginální proporce (nebo četnosti) kategorií. Zápis musí mít následující formu: kód první kategorie, požadovaná proporce (nebo četnost), kód následující kategorie atd., přičemž jednotlivé hodnoty se oddělují mezerou.
Nepovinně lze v poli Population Total určit také požadovaný celkový součet vah (pokud je jiný než počet případů v datovém souboru). Tlačítka Options a Plots umožňují nastavit kritéria iterace a doplňující výstupy.
Procedura má rovněž vlastní syntaxový příkaz SPSSINC RAKE.
Výstupem je vyvážený datový soubor a další doplňující výstupy (například histogram zobrazující rozložení vah).
Příklad 2 – užití skriptu pro obarvení tabulky
Skript Obarveni_tabulky_linearni.py obarví požadovanou tabulku nebo její část dle nastavení v úvodním dialogu. Barvení může být založeno na jednom, nebo dvou barevných odstínech, přičemž intenzita barvy lineárně roste/klesá v závislosti na obarvovaných hodnotách. Jedná se o velmi oblíbený skript, který je pro zákazníky ACREA CR zdarma k dispozici ke stažení na stránkách. Jeho užití si ukážeme na příkladu korelační matice.
Postup realizujeme v několika jednoduchých krocích:
- Pomocí nabídky Analyze, Correlate, Bivariate vytvoříme korelační matici vybraných proměnných.
- Tabulku přepivotujeme tak, aby horní vrstva obsahovala pouze Pearsonův lineární korelační koeficient, ostatní statistiky přesuneme do vrstev.

- Před spuštěním skriptu tabulku označíme.
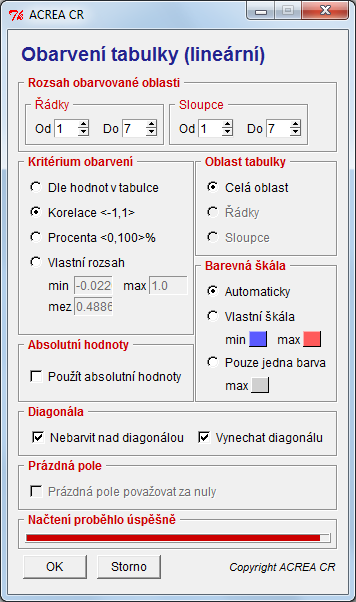
- Spustíme skript py. V následujícím dialogu nastavíme v části Kritérium obarvení volbu Korelace, zaškrtneme políčka Nebarvit nad diagonálou a Vynechat diagonálu a potvrdíme tlačítkem OK.
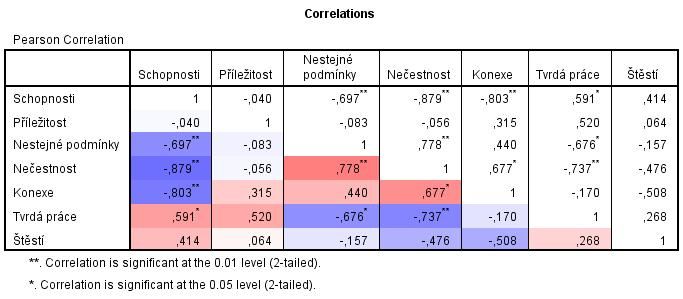
Tabulka se následně obarví tak, že v intervalu od -1 do 0 se lineárně snižuje intenzita modré barvy od RGB=(90,90,255) až do bílé, v intervalu od 0 do 1 lineárně roste intenzita červené barvy od bílé až do RGB=(255,90,90). Záporné korelace se tedy podbarví modrou barvou, kladné červenou a nule odpovídá bílá. Čím sytější barva, tím silnější korelace. Krajní odstíny barev lze rovněž nastavit podle potřeb uživatele.
Rádi byste se o statistice a analýze dat dozvěděli více? Chcete se stát mistrem ve svém oboru nebo si jen potřebujete doplnit znalosti? V ACREA nabízíme širokou nabídku kurzů pro váš profesní růst. Máte-li jiný dotaz. Nebojte se využít naši nezávaznou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení.

