6 nejčastějších chyb při vizualizaci

Vizualizace dat je součástí každé analýzy a umožňuje nám prezentovat její výsledky. Při vytváření grafických výstupů je nutno dodržovat několik základních pravidel. V článku shrneme některé časté chyby, které se mohou při vizualizaci dat vyskytnout.
1. Zdroj dat
Kvalita výsledné vizualizace dat závisí v první řadě na zdroji dat. Především pokud přebíráte data z jiného zdroje, je důležité si ověřit jejich správnost. V opačném případě byste mohli skončit s dobře vypadajícím grafem, který by zobrazoval zcela nesprávné informace.
2. Velké množství informací
Další problém může nastat, pokud do vizualizace zahrnete velké množství údajů. Zahltíte tím koncového uživatele a nebude schopen z takového grafu vyčítat ty nejdůležitější informace. Tento fenomén se nazývá informační přetížení a může vést až k úplné ztrátě pozornosti. Možným řešením je data rozdělit do více samostatných grafů tak, aby byly srozumitelnější, případně některé méně zastoupené kategorie sloučit.
Následující graf zobrazuje odpověď respondentů z evropského sociálního šetření z roku 2018. U respondentů se zjišťovala kromě jiných charakteristik úroveň vzdělání a to, jak moc se zajímají o politiku. Pro zobrazení odpovědí na tyto dvě otázky byl použit skládaný sloupcový graf. Vzhledem k podrobnému dělení do kategorií vzdělání a jejich náhodnému uspořádání je složité si udělat ucelený obraz o tom, jak se zájem o politiku pro jednotlivé stupně vzdělání liší.
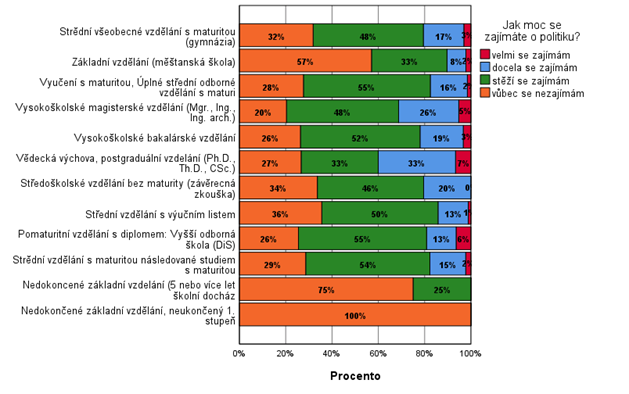
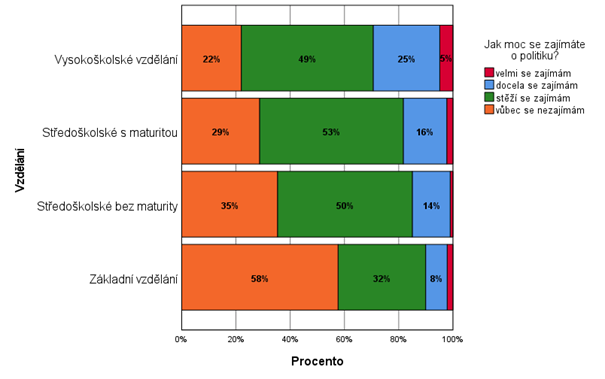
Druhý graf zobrazuje odpovědi na tytéž otázky. Hlavní rozdíl je v počtu kategorií, které byly sloučeny z 12 na 4. Jednotlivé kategorie byly následně ještě seřazeny podle stupně vzdělání od toho nejnižšího po nejvyšší. Z takového grafu je už na první pohled zřejmé, že zájem o politiku se stoupající úrovní vzdělání roste.
3. Data bez kontextu
Jednou z častých chyb při vizualizaci dat je jejich prezentace bez dalšího kontextu. Při tvorbě grafu počítejme s tím, že jeho koncový uživatel nebude mít tolik informací jako jeho tvůrce. Proto je důležité zvolit co nejvýstižnější název grafu, jednotlivé osy by měly mít popisky, v případě kategorizovaných proměnných je třeba přidat seznam kategorií.
4. Zkreslené škály
Úprava rozsahu os může vést k vytvoření jinak vypadajícího grafu. Častou chybou je taková úprava škály, kdy se nepřiměřeně zvýrazní rozdíly mezi jednotlivými kategoriemi. To rozhodně není správný postup. Výrazný vliv na interpretaci může mít i řazení kategorií. V tomto směru je pro přehlednost vhodnější seřadit nominální kategorie podle hodnoty sledovaného znaku.
Následující graf zobrazuje průměrnou hodnotu důvěry v právní systém pro voliče jednotlivých stran v roce 2018. Výsledná hodnota vznikla prostým zprůměrováním důvěry jednotlivých respondentů, která se mohla pohybovat na škále 1-10 (čím vyšší hodnota, tím vyšší důvěra). Z tohoto grafu se zdají být rozdíly mezi některými stranami, například ČSSD a SPD, zcela zásadní. Tomu přispívá jednak ořezaná škála osy y ale také to, že hodnota ukazatele díky nevhodnému řazení stran několikrát klesá a znovu roste.
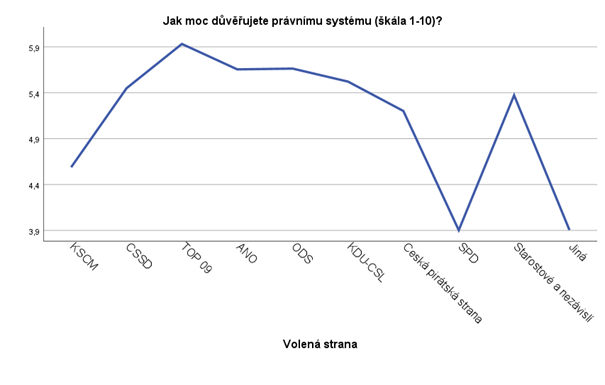
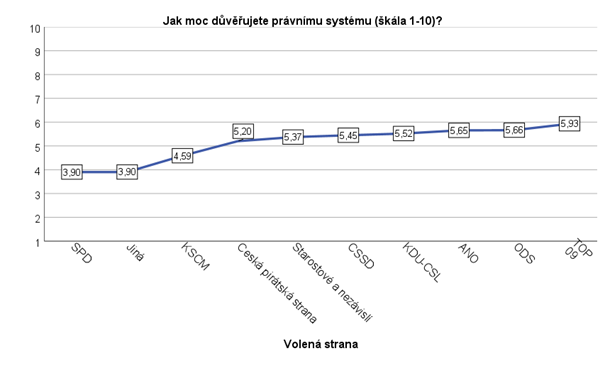
Ve druhém grafu není škála osy y upravena a strany jsou seřazeny od nejnižší hodnoty po nejvyšší. Pro větší přehlednost jsou ještě do grafu přidány samotné hodnoty důvěry pro voliče jednotlivých stran.
5. Výběr špatné vizualizační metody
Typ grafu předurčuje jeho využití. Například koláčové grafy se používají k zobrazení jednotlivých částí celku. Fungují dobře třeba i při zobrazení věkové struktury obyvatelstva. Pokud ale potřebujeme pomocí tohoto grafu zobrazit měnící se výnosy tří rozdílných firem, byl by už vhodnějším nástrojem graf sloupcový, kde se více zvýrazní rozdíly mezi jednotlivými firmami.
Před tvorbou grafu je tedy nutné zamyslet se nad tím, co chceme jeho prostřednictvím sdělit.
6. Využívání grafů jako takových
Ne vždy je vizualizace dat nezbytná. Pokud lze údaje jasně a stručně odprezentovat pomocí jednoduché popisné statistiky, není nutné využívat grafického zobrazení. I zde platí dřívější principy. Uživatele bychom neměli zahltit velkým počtem údajů a méně známých metrik. Výsledný číselný popis by měl být co nejstručnější.
Následující graf je toho příkladem. Sloupce tohoto grafu představují průměrnou důvěru respondentů ve vybrané instituci. V tomto případě lze jednotlivé průměry zobrazit i v tabulce, ta nám kromě toho umožňuje hodnotu průměru doplnit i o další statistiky, které bychom pomocí grafu nebyli schopni prezentovat, jako je například směrodatná odchylka.


Dodržování popsaných pravidel může pomoci nejen tvůrci, ale i uživateli daných výstupů. Pokud Vás tento článek zaujal a chtěli byste se dozvědět více o vizualizaci a reportování dat přihlaste se na náš kurz Reportování a vizualizace statistických dat.


Dobrý den,
dovolím si nesouhlasit s posledním příkladem. Směrodatná odchylka se do grafu přece lehko přidá pomocí chybových úseček. Naopak tabulkové uspořádání mi zde přijde zbytečně detailní. A rovněž zmíněné zobrazení věkové struktury ve výsečovém grafu mi zvedá obočí, ale třeba by mě výsledek přesvědčil 😉
Dobrý den,
přidání chybových úseček do grafu je určitě možné a používané řešení, při větším počtu proměnných/kategorií ale nemusí být nutně tím nejpřehlednějším. Co se týče zmíněného příkladu použití výsečového grafu při zobrazení věkové struktury, využívá se u této charakteristiky hlavně z důvodu, že jeho výseče budou v součtu představovat 100% (tedy celou populaci např. ČR). Tento konkrétní graf využívá pro zobrazení věkové struktury například i eurostat v některých svých publikacích. Určitě ale můžete využít pro zobrazení takové proměnné i graf sloupcový, který se často využívá právě u proměnných, jejichž škála je ordinální, což je i příklad zmíněné proměnné věk.