Procedury pro přípravu dat: optimální kategorizace

Ve třetím článku ze série o procedurách pro přípravu dat v IBM SPSS Statistics si představíme proceduru Optimal Binning, která umožňuje kategorizovat číselnou proměnnou optimálním způsobem vzhledem k cílové kategorizované proměnné. Ve verzi 27 je nově zařazená do základního modulu Base (dříve modul Data Preparation).
K čemu je užitečná procedura Optimal Binning
Kategorizaci číselné proměnné lze provést mnoha různými způsoby. Většina z nich vychází pouze z rozložení dané proměnné – cílem je například zajistit, aby byly intervaly stejně široké, kategorie pokud možno stejně zastoupené, nebo oddělit vzdálenější hodnoty definované jako průměr +/- zvolený násobek směrodatné odchylky. Někdy je však nutné brát v úvahu také chování této proměnné vzhledem k jiné cílové proměnné.
Procedura Optimal Binning je určená k optimální kategorizaci jedné nebo více číselných proměnných vzhledem k dané kategorizované proměnné. Hledá tedy takové body, které rozdělí hodnoty vstupní proměnné do intervalů tak, aby výsledná proměnná měla co nejsilnější vztah k cílové proměnné. Nově odvozenou kategorizovanou proměnnou (proměnné) lze následně užít pro další analýzu. Algoritmus je založený na metodě MDLP (minimal description length principle) a na statistice Entropie.
Tento přístup nachází široké uplatnění při přípravě dat pro modelování. Například před užitím logistické regrese i dalších metod, které jsou citlivé na extrémní hodnoty nebo silně zešikmená data, je vhodnější vstupní proměnné s problematickým rozloženým nejprve kategorizovat. V řadě situací je však předmětem zájmu přímo nalezení dělicích bodů – například v medicíně při zkoumání, jaké hodnoty určitého parametru jsou již rizikové vzhledem k určitému onemocnění.
Způsob zadávání
Dialogové okno procedury otevřeme z nabídky Transform, Optimal Binning.
Na záložce Variable zadáme do pole Variables to Bin číselné proměnné, které mají být kategorizovány, a do pole Optimize Bins with Respet To kategorizovanou proměnnou, vzhledem k níž má být kategorizace optimální.
Na záložce Output označíme požadované výstupy:
- Endpoints for bins – nalezené optimální dělicí body pro každou kategorizovanou vstupní číselnou proměnnou a četnosti řídící kategorizované proměnné ve skupinách,
- Descriptive statistics for variables that are binned – popisné statistiky vstupních číselných proměnných (počet, minimum, maximum, počet různých hodnot a počet nalezených dělicích bodů),
- Model entropy for variables that are binned – hodnota statistiky Entropie pro každou kategorizovanou vstupní číselnou proměnnou vzhledem k řídící kategorizované proměnné.
Na záložce Save volíme, jaké informace mají být uloženy.
V části Save Variables to Active Dataset určíme, zda mají být kategorizované proměnné uloženy do datové matice (Create variables that contain binned data values) a zda v případě konfliktu názvů mají být nahrazeny dříve vytvořené proměnné (Replace existing variables that have the same name).
V části Save Binning Rules as Syntax lze zadat uložení pravidel pro odvození kategorizovaných proměnných do syntaxe.
Na záložce Missing Values volíme způsob práce s vynechanými hodnotami:
- Pairwise – pro každou dvojici (číselná proměnná a řídící kategorizovaná) samostatně,
- Listwise – pokud má kterákoliv ze vstupních proměnných vynechanou hodnotu, je případ vyloučen.
Uživatelem definované vynechané hodnoty jsou vždy považované za neplatné a při kategorizaci jsou převedeny na systémové vynechané hodnoty.
Na záložce Options lze provést další nastavení, která se týkají urychlení algoritmu pro velké datové soubory (Preprocessing), spojení řídce zastoupených kategorií (Sparsely Populated Bins), rozhodnutí, do které z kategorií budou zahrnuty dělicí body (Bin Endpoints) a zda krajní kategorie budou od mínus nekonečna resp. do plus nekonečna nebo budou začínat nejnižší resp. končit nejvyšší hodnotou v datech.
Příklad
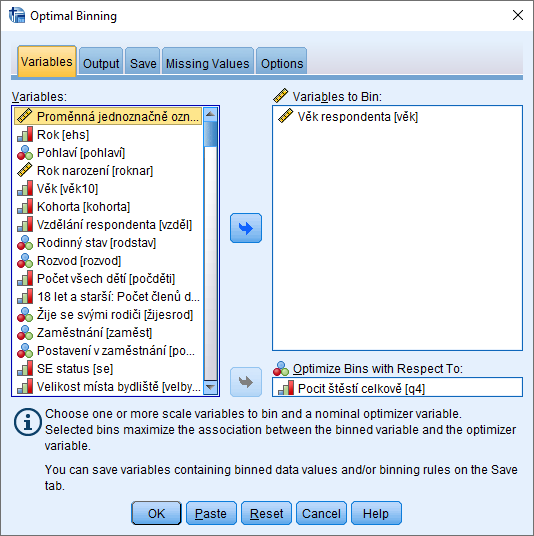
Užití procedury Optimal Binning si ukážeme na příkladě kategorizace věku vzhledem k proměnné Pocit štěstí celkově. Tato proměnná je hodnocena na škále od 1= „vůbec ne šťastný/á“ do 4= „velmi šťastný/á“. Rozložení četností v souboru zobrazuje následující tabulka.
V dialogovém okně procedury Optimal Binning na záložce Variable zadáme do pole Variables to Bin proměnnou Věk respondenta, do pole Optimize Bins with Respect To proměnnou Pocit štěstí celkově. Na záložce Save označíme volbu Create variables that contain binned data values.
Ve výstupovém okně se zobrazí následující tabulka, která doporučuje jako optimální rozdělit věk do dvou kategorií: méně než 39 let a 39 a více let. Dále jsou zde zobrazené četnosti proměnné Pocit štěstí celkově v těchto skupinách.
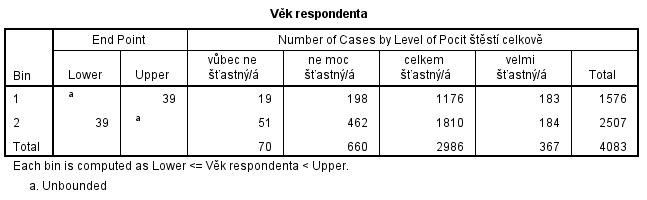
Zároveň se v datové matici vytvořila nová proměnná s takto definovanými kategoriemi, kterou můžeme využít pro další analýzu. Pojmenujeme ji Věkové kategorie.
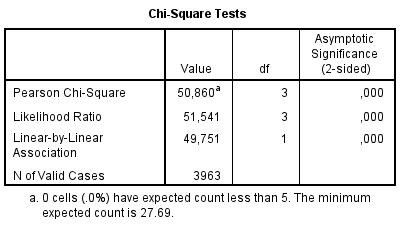
Pro přehlednější porovnání pocitu štěstí v takto odhozených věkových kategoriích využijeme proceduru Crosstabs. Z řádkových procent je vidět, že ve skupině méně než 39 let jsou více zastoupené kategorie celkem šťastný/á a velmi šťastný/á. Naopak ve věkové skupině 39 a více let se častěji vyskytují odpovědi vůbec ne šťastný/á a ne moc šťastný/á
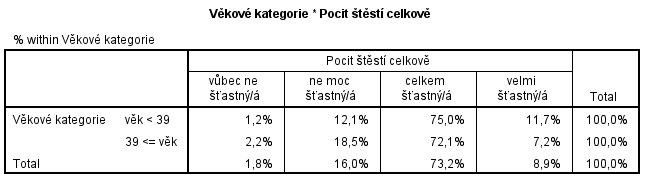
Výsledek testu chí-kvadrát (tabulka Chi-Square Tests, řádek Pearson Chi-Square) ukazuje, že skupiny se od sebe statisticky významně liší.