Jak poznat, že náš dataminingový model je dobrý? (část druhá)

Dnešní článek navazuje na předcházející text Jak poznat, že náš data miningový model je dobrý? věnovaný evaluačním grafům Gains a ROC. Křivek pro vyhodnocení kvality supervizovaných modelů s dichotomickou cílovou proměnnou však existuje mnohem více, proto se nyní seznámíme s dalšími dvěma typy grafů, konkrétně Lift a Profit chart.
Stejně jako v předchozím článku budou grafy popisovat situaci z prostředí zdravotních pojišťoven, kdy se pojišťovna snaží podpořit zdraví svých klientů. Za tímto účelem si pojišťovna sestavila dataminingový model, aby díky němu dokázala včas určit, který její pojištěnec je pravděpodobně nemocný a měl by se začít vhodně léčit. Vytvořený klasifikátor má tedy za cíl u každého pojištěnce určit, zda trpí danou nemocí (1) či nikoliv (0).
U obou evaluačních grafů Lift i Profit se na vodorovné ose nacházejí jednotlivé případy z datové matice (v našem případě pojištěnci) seřazené podle velikosti skóre a zobrazené pomocí percentilů. Na svislé ose je pak vynesen příslušný evaluační ukazatel.
Lift
Lift říká, kolikrát se zvýší spolehlivost výběru oproti náhodě. Hodnota Lift se počítá jako podíl aposteriorní a apriorní pravděpodobnosti, proto u této křivky nemusí být na svislé ose hodnoty mezi 0 a 1. Pokud tuto definici převedeme do kontextu námi uvažovaného příkladu zdravotní pojišťovny, můžeme Lift vypočítat podle následujícího vzorce:
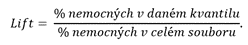
Čím vyšší číslo získáme, tím se nám podařilo nalézt lepší model, co se týče přesnosti jeho výsledků.
Při porovnávání několika modelů mezi sebou je však potřeba mít na paměti, že maximální hodnota statistiky Lift se pro různá data (nebo pro různé výběry z dat) liší. Nejvyšší možný Lift lze pro konkrétní model určit jako podíl čísla 100 a procenta pozitivních případů (tzv. zásahů) v celém zkoumaném souboru.
V popisovaném příkladu je maximální možná hodnota Liftu rovna 2,175, protože se v použitém datovém souboru nachází celkem 8,7 tis. pojištěnců a z toho 4 tis. osob trpí danou nemocí.
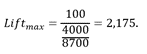
Ve čtvrtém decilu se Lift pohybuje kolem hodnoty 1,86 (bod označený oranžovým kolečkem). To znamená, že pokud by pojišťovna zařídila vyšetření pro 40 % svých pojištěnců seřazených podle výsledných hodnot skóre získaného z dataminingového modelu, tak by odhalila téměř dvakrát (1,86krát) více nemocných osob, než kdyby klienty vybírala na vyšetření náhodně.
Profit
Profit vyjadřuje vyčíslitelný přínos sestaveného modelu. Ten je nejčastěji uváděn v penězích, ale může být také popisován pomocí jiných ukazatelů, jako je například úspora času. Pro sestavení grafu Profit je tudíž nezbytné znát náklady a výnosy na zkoumanou jednotku.
V našem ukázkovém příkladu by zdravotní pojišťovna ráda odhalila nemoci u pojištěnců v jejich počátečních fázích. Tím by pojišťovna zároveň dokázala uspořit náklady spojené s úhradou léků, neboť léčba nemoci v její počáteční fázi je méně finančně náročná než u rozvinuté formy nemoci, kdy se pacient musí léčit delší dobu.
Uvažujme, že v případě včasného zachycení nemoci bude léčba pacienta pojišťovnu stát 250 Kč, naopak léčba v pokročilém stádiu vyjde na 1 150 Kč. Aby mohla být nemoc včas rozpoznána, pozve pojišťovna vybranou osobu na lékařské vyšetření, jehož cena činí 150 Kč.
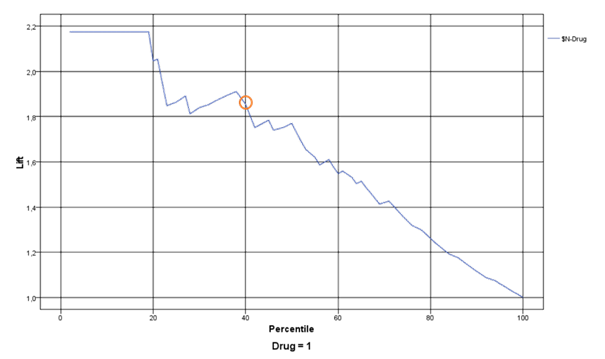
Podle výsledků grafu Profit je zřejmé, že největší úspory pojišťovna dosáhne, když pozve na lékařskou prohlídku 50 % ze svých klientů seřazených podle modelu (bod označený oranžovým kolečkem). V takovém případě za včasnou léčbu ušetří na testovacím výběru klientů celkem 892 tis. Kč oproti situaci, kdy by žádnou preventivní akci nepodnikla a pacienti by k lékařům přicházeli až s pokročilými stádii nemoci. Jinými slovy to znamená, že prostřednictvím dataminingového modelu pojišťovna může ušetřit 103 Kč u každého svého klienta, což na celém jejím portfoliu bude znamenat úspory v řádech milionů Kč.
Naopak v případě, že by pojišťovna chtěla provést lékařské vyšetření u všech svých pacientů, náklady na vyšetření by převýšily potenciální úsporu peněžních prostředků za včasnou léčbu a pojišťovně by vznikla ztráta 480 tis. Kč oproti situaci, než kdyby žádný preventivní program nedělala (označeno zeleným kolečkem).
Kromě uváděných grafů Lift a Profit existují ještě mnohé další evaluační křivky. Například Kolmogorov-Smirnovův graf popisuje, obdobně jako graf Gains, vztah senzitivity a (1-specifičnosti), avšak navíc v závislosti na velikosti skóre. Další z evaluačních grafů Response pak vystihuje závislost přesnosti na percentilu skóre a určuje se jako podíl počtu zásahů v daném kvantilu a počtu zásahů v celém datovém souboru. Křivka Response tvarově odpovídá grafu Lift, liší se od sebe měřítky na svislé ose y, kdy u Response je maximální hodnota osy rovná 100 %. Příkladem další evaluační křivky je ROI, jenž vyjadřuje podíl výnosů a nákladů v daném kvantilu. Graf ROI udává, jaké jsou přínosy cílení pomocí modelu vzhledem k tomu, kolik investujeme.
V případě, že byste se rádi dozvěděli o evaluačních technikách a celém data miningu více, doporučujeme se podívat na aktuální nabídku dataminingových kurzů.

