Jak poznat, že náš dataminingový model je dobrý?

V dnešní době, kdy je snahou každé organizace vytěžit ze svých dat co nejvíce informací, je v rámci řešení dataminingových úloh vytvářeno velké množství různých modelů. Nicméně spolu se zrodem každého modelu vzniká také potřeba ověřit správnost jeho výsledků a vyhodnotit, zda je „dostatečně dobrý“ a jestli jej vůbec lze nasadit do praxe. A právě touto částí modelování, která se nazývá evaluace, se budeme zabývat v dnešním článku. Jelikož tato fáze data miningového projektu je velice obsáhlá, zaměříme se pouze na grafické vyhodnocení kvality modelů, kdy si představíme dva základní typy evaluačních grafů, a to Gains a ROC.
Avšak dříve, než se pustíme do interpretace samotných evaluačních křivek, je nezbytné si objasnit několik základních pojmů používaných při vyhodnocování kvality supervizovaných modelů. Jedním z nejčastěji používaných evaluačních ukazatelů u klasifikátorů, které predikují dichotomickou proměnnou, je senzitivita. Tato statistika říká, kolik procent ze skutečně pozitivních případů byl model schopen odhalit. Z matice záměn senzitivitu spočítáme jako TP / (FN + TP). Specifičnost (specificita) naopak udává, jakou část z počtu skutečně negativních případů model správně označil jako negativní. Z matice záměn ji získáme jako podíl TN / (FP + TN).
Skóre je číslo úměrné pravděpodobnosti, že jedná o pozitivní kategorii (tzv. zásah). Skóre je uvedeno u každého případu datové matice a podle jeho hodnoty se určuje výsledná kategorie predikce. Případ je predikován jako pozitivní, pokud jeho skóre překročí prahovou hodnotu skóre. Výhoda je, že většina dnešních analytických nástrojů už zmíněné evaluační ukazatele rovnou automaticky vypočítá.
Evaluační grafy budou popisovány na výsledcích fiktivního dataminingového modelu pojišťovny, jehož cílem bylo na základě několika vstupních proměnných rozeznat nemoc u pojištěnce a tím zajistit jeho včasnou léčbu. Pojišťovna by díky modelu ráda předešla vážnějším průběhům nemocí u svých klientů. Zkoumaná cílová proměnná je binomická neboli nabývá pouze dvou hodnot: osoba je nemocná (1) a osoba není nemocná (0).
Gains
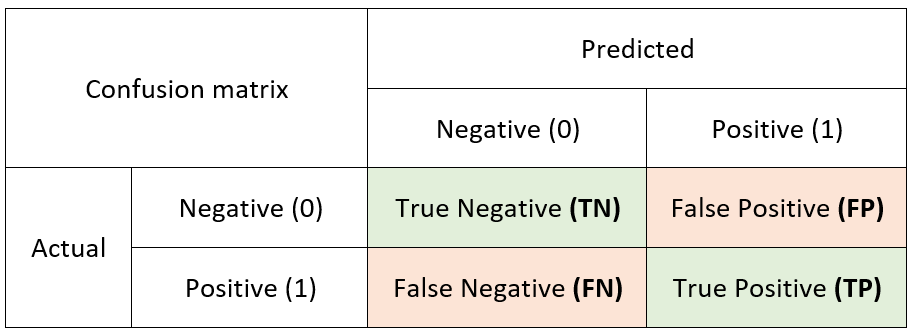
První z ukazovaných evaluačních křivek je Gains. Na vodorovné ose jsou vyneseny percentily datového souboru seřazeného podle velikosti skóre. Na svislé ose jsou pak uvedeny procenta osob, které mají pozitivní odpověď na zkoumaný problém – v našem příkladě ti, kteří jsou opravdu nemocní (senzitivita).
Zelená křivka v grafu představuje výsledky klasifikátoru vzorového příkladu. Z hodnot je patrné, že pokud bychom u prvních 46 % ze všech seřazených pojištěnců udělali cílené vyšetření, tak nalezneme 80 % z těch, kteří jsou ve skutečnosti nemocní a léčbu potřebují (bod označený oranžovým kolečkem).
Modrá křivka v grafu naopak ukazuje, že pokud by se nám podařilo sestavit ideální model, tak bychom po vyšetření 46 % pojištěnců získali všechny osoby (100 %), kteří mají sledovanou nemoc (žluté kolečko). V takovém případě by byli k lékařskému vyšetření vybráni pouze skutečně nemocní pojištěnci, a tedy žádné osoby, které nemocí netrpí. Křivka ideálního modelu ve vzorovém příkladě dosahuje na svislé ose hodnoty 100 v bodě procentuální pozitivity na celkovém datovém souboru (celkový počet nemocných dělený počtem všech pojištěnců).
Do grafu Gains se také často vykresluje křivka náhodného výběru (červená přímka). Ta představuje situaci, kdyby žádný data miningový model nebyl použit a pojišťovna by klienty na lékařské vyšetření posílala náhodně. V takovém případě by u poloviny vyšetřených pojištěnců byla odhalena pouze polovina skutečně nemocných osob (bod označený modrým kolečkem).
ROC
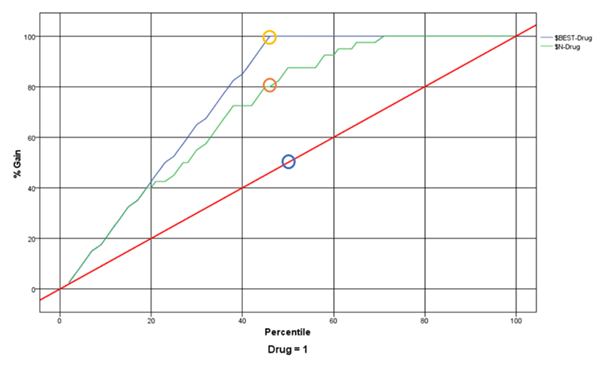
Druhou dnes popisovanou evaluační metodou je vykreslení ROC křivky, která představuje zřejmě nejpoužívanější typ grafu pro binární klasifikátory. ROC zobrazuje všechny možné kombinace senzitivity a specificity, které lze daným modelem získat. Na vodorovné ose je vynesena hodnota 1 – specifičnost, na svislé ose pak senzitivita. Pomocí ROC křivky se snažíme najít nejvhodnější kombinaci vysoké senzitivity i specificity. Čím blíže je ROC křivka našeho modelu k levému hornímu rohu sítě grafu (a zároveň dále od červené diagonály), tím model poskytuje lepší výsledky klasifikace (viz směr zelené šipky v grafu).
Křivka zachycující výsledky sestaveného modelu je označena modrou barvou. Například bod vyznačený oranžovým kolečkem udává, že model poskytuje výsledky se senzitivitou rovnou 0,875 při specifičností 0,800. Uvedenou hodnotu specifičnosti sice přímo v grafu nejde najít, ale snadno ji lze dopočítat, a to jako doplněk do jedné k údaji na vodorovné ose, tedy 1 – 0,2 = 0,8.
V uvedeném příkladě to konkrétně znamená, že při použití modelu se zvolenou prahovou hodnotou skóre je model schopen odhalit 87,5 % z těch osob, které ve skutečnosti jsou nemocné. Zároveň model dokáže správně určit 80 % pojištěnců, kteří nemoc nemají. Nicméně to také znamená, že by pojišťovna zbytečně poslala na vyšetření jednu pětinu osob, které nemocné nejsou a léčit se nepotřebují. Z tohoto důvodu je velice důležité nesledovat pouze senzitivitu daného modelu, ale také se dívat na jeho specifičnost.
Červená křivka opět představuje situaci bez jakéhokoliv data miningového modelu.
Křivka ROC je často konstruována s cílem získat další evaluační statistiky, jako jsou AUC (plocha pod modrou křivkou) a Giniho koeficient (dvojnásobek plochy mezi modrou křivkou a červenou diagonálou).
Závěrem je vhodné zmínit, že ověřování kvality modelu musí vždy probíhat na datech, které model při učení neměl k dispozici, tedy na nějakém testovacím souboru. Také není vhodné při evaluaci sledovat pouze měřitelné statistiky, ale je potřeba zohlednit i jiné aspekty vytvořeného modelu, jako jsou jeho transparentnost, možnost aktualizace či složitost způsobu nasazení do praxe.
Pokud byste se chtěli o evaluačních technikách a celém data miningu dozvědět více, lze získat tyto znalosti v našich dataminingových kurzech.

