Diskriminační analýza a logistická regrese III.

V minulé části jsme si ukázali, jak se v diskriminační analýze provádí klasifikace do skupin. Používají se dva, co se výsledku týče, ekvivalentní způsoby, kdy jeden pracuje s diskriminačními funkcemi a druhý s funkcemi klasifikačními. Nyní přikročíme k srovnání klasifikace s další široce rozšířenou metodou pro klasifikaci, tedy s logistickou regresí. Logistická regrese počítá pravděpodobnost příslušnosti ke skupině podle vzorce (1).
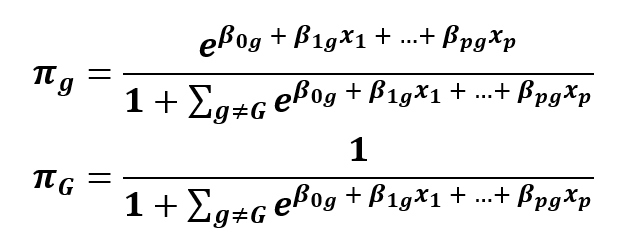
Kde G odpovídá jedné zvolené skupině (reference) a g jsou ostatní skupiny. Vzorec je platný i pro klasifikaci do dvou skupin, pak lze jednu pravděpodobnost získat také jako doplněk do jedné. Protože je vzorec založen na původních proměnných, a ne na diskriminačních funkcích, je pro srovnání s DA vhodné použít klasifikaci založenou na klasifikačních funkcích pracujících s původními proměnnými, vzorec (2).
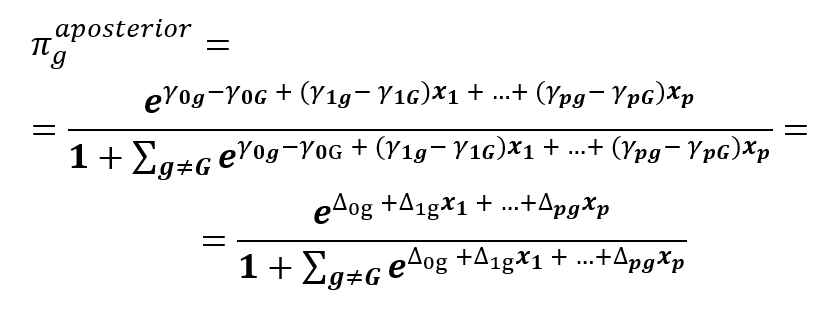
Srovnání obou vzorců ukazuje analogický výpočet pravděpodobnosti (aposteriorní). Srovnáním zjistíme, že koeficientům logistické regrese β1g odpovídá rozdíl klasifikačních funkcí Δ1g. To, čím se vzorce liší, je způsob odhadu koeficientů a tím i jejich intepretace. Interpretaci DA jsme si ukázali v minulém článku, nyní se zaměříme na logistickou regresi.
Interpretace
V logistické regresi mají koeficienty jasnou intepretaci, vyjadřují kolikrát se změní šance pro danou skupinu oproti referenční při jednotkové změně proměnné. Šance je podíl pravděpodobností příslušnosti k jedné a ke druhé skupině. V logistické regresi se předpokládá lineární závislost logaritmu šance na vysvětlujících proměnných, to vede ke vzorci (1). Koeficienty se odhadnou metodou maximální věrohodnosti tak, aby vzorec co nejvěrněji zachycoval empirické šance. Dá se ukázat, že exponenciála z koeficientu stojícího u dané proměnné exp(β1g) vyjadřuje, kolikrát se zvýší šance, pokud se proměnná zvýší o 1. Mluvíme o poměru šancí (OR, odds ratio).
Pro srovnání s diskriminační analýzou je potřeba dát koeficientům i geometrickou intepretaci. Pro jednoduchost se omezíme na dvě nezávislé proměnné a dvě skupiny. Při více skupinách by se srovnávaly po dvojicích. Pro srovnání dvou skupin máme ve vzorci (1) jen jednu rovnici, která počítá pravděpodobnost jedné skupiny, řekněme A. Pravděpodobnost druhé skupiny B se dopočítá jako doplněk do 1.
Omezíme-li se jen na dvě proměnné, je ve vzorci (1) v exponentu rovnice přímky, podél které jsou pravděpodobnosti příslušnosti ke skupině konstantní, konstantní je tudíž i šance. Šance roste nejrychleji ve směru kolmém na tuto přímku a odhad se snaží co nejvěrněji replikovat směr růstu šance v souboru. Konkrétní pozice přímky v rovině závisí na hraniční pravděpodobnosti, případ je přiřazen ke skupině A, pokud její pravděpodobnost překročí hranici. Hraniční pravděpodobnost hraje podobnou roli jako apriorní pravděpodobnost v diskriminační analýze.
V DA je směr hraniční přímky dán zejména polohou centroidů skupin a vnitrokovarianční maticí, poloha závisí ještě na apriorních pravděpodobnostech. Jednotlivý případ ovlivňuje hranici pouze zprostředkovaně přes průměry a vnitrokovarianční matice, dva různé soubory ale se stejnými centroidy a vnitrokovariančními maticemi by vedly k identické DA. V logistické regresi případ ovlivňuje přímo odhadnutou rovnici. Přestože jsou vzorce (1) a (2) formálně shodné, nelze exponenty koeficientů DA interpretovat jako OR, koeficienty jsou vždy jen odhady a DA s OR vůbec nepracuje, takže je ani neodhaduje.
Srovnání
Navzdory odlišné interpretaci je užitečné koeficienty srovnat, pokud se příliš neliší, je to dobrým znamením, že určení skupin je robustní a lze ho odhadovat různými způsoby. Vliv proměnných bude podobný, pokud budou hraniční přímky, resp. vícerozměrné nadroviny obou metod rovnoběžné. Absolutní pozice v prostoru není podstatná, hranice lze vždy posouvat volbou hraniční pravděpodobnosti nebo apriorních pravděpodobností. Rovnoběžnost obecně neznamená rovnost koeficientů. Přímka se totiž nezmění, když její obecnou rovnici vynásobíme konstantou, např. rovnice y + 2x + 5 = 0 definuje stejnou přímku jako rovnice 3y + 6x + 15 = 0. Koeficienty obou metod je proto nutno pro srovnání normalizovat nejlépe tak, že vytkneme koeficient u jedné proměnné a porovnáme ostatní koeficienty. Neporovnáváme absolutní člen, který definuje nezajímavou pozici v prostoru. V Tab. 1 je ukázka původních a normalizovaných koeficientů, pro DA je uveden už rozdíl klasifikačních funkcí. Na Obr. 1 je nakreslena odpovídající hraniční přímka z obou metod, v tomto případě jsou přímky nejen přibližně rovnoběžné, ale téměř splývají. Důležitá je ovšem rovnoběžnost.
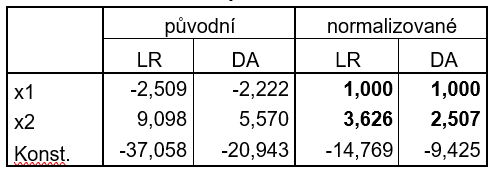
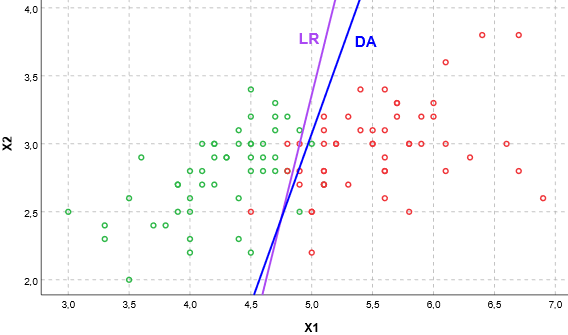
Pro praktické užití se nabízí zřejmá otázka, kterou metodu použít. Na ní je zřejmá odpověď: „To záleží…“. Záleží na tom, jakým mechanismem se v realitě řídí příslušnost ke skupině a který model je tudíž realitě bližší. To obecně nelze určit. Formálně se lze zaměřit na předpoklad vícenásobné normality u DA, ale jeho největší porušení, sešikmené a extrémní hodnoty, má stejně devastující vliv i na LR, ač ta normalitu nepředpokládá.
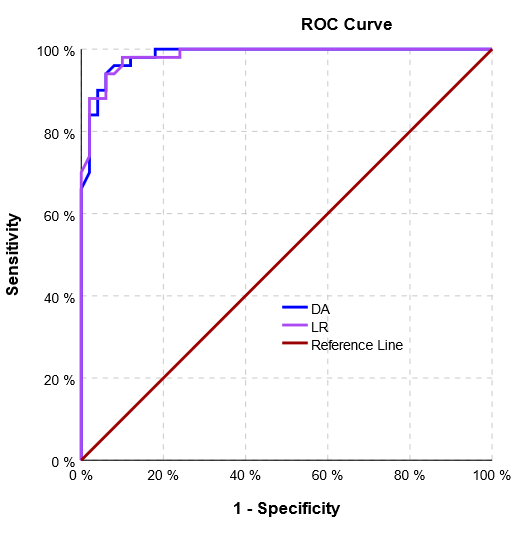
Nejlepší je srovnat klasifikační schopnost obou metod. V případě dvou skupin je vhodné přímé užití ROC křivky, v případě více skupin postupné srovnání pomocí jednotlivých párů opět podle ROC. Situace je usnadněna jsou-li hraniční přímky (nadroviny) rovnoběžné, pak obě metody dávají podobné výsledky. Jako je na Obr. 2 odpovídající klasifikaci z Obr. 1.
Záleží také na potřebě intepretace. U DA je velmi neintuitivní, je pouze geometrická a představitelná jen ve dvourozměrném, maximálně třírozměrném prostoru. Není to však žádná věcná intepretace s ohledem na zkoumaný problém. Nejvíce uchopitelnou intepretaci dostaneme nakonec srovnáním s koeficienty LR (původní, ne normalizované), ale pak můžeme rovnou odhadnout LR. DA také neobsahuje žádné testy koeficientů. Pokud je věcná intepretace nutná, je LR v podstatě jedinou volbou a zříkáme se jí jen, když DA dává výrazně lepší výsledky.
Rádi byste se o statistice a analýze dat dozvěděli více? Chcete se stát mistrem ve svém oboru nebo si jen potřebujete doplnit znalosti? V ACREA nabízíme širokou nabídku kurzů pro váš profesní růst. Máte-li jiný dotaz. Nebojte se využít naši nezávaznou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení.

