Bootstrapping – aneb jak souvisí statistika s řemínky na botách

Jednou ze změn ve verzi IBM SPSS Statistics 27 je zařazení nástrojů původního modulu Bootstrapping do základního modulu Base. Díky tomu jsou nyní dostupné mnohem širšímu okruhu uživatelů. V dialogovém okně celé řady standardních statistických procedur je k dispozici tlačítko Bootstrap, pomocí něhož lze zadat výpočet robustních odhadů standardních chyb a intervalů spolehlivosti na základě metody bootstrap pro odhady statistik jako například průměr, medián, proporce, podíl šancí, korelační koeficient nebo regresní koeficienty. V tomto článku si podrobněji přiblížíme, co je bootstrapping, ukážeme si, jak zadat výpočet bootstrapových odhadů i jaké typy výstupů se následně zobrazují. Na závěr si také zodpovíme otázku skrytou v nadpisu článku.
Bootstrapping
Bootstrapping (někdy též bootstrap) je statistická metoda založená na výběrech s opakováním z jednoho datového souboru. Tímto způsobem se vytvoří velké množství simulovaných výběrů (tzv. bootstrapových výběrů), jejichž rozsah je obvykle stejný jako rozsah původního souboru. Na základě těchto výběrů a odhadů sledovaného parametru v každém z nich, lze získat robustní odhady standardních chyb a intervalů spolehlivosti. Metodu je však možné využít i pro testy hypotéz. Tento přístup poprvé publikoval v roce 1979 americký statistik Bradley Efron v článku Bootstrap methods: another look at the jackknife a od té doby se stal velmi populární. Řadí se mezi počítačově intenzivní statistické metody.
Bootstrapping představuje velmi užitečnou alternativu k parametrickým odhadům v situacích, kdy nejsou dobře splněné předpoklady těchto metod, parametrické odhady nejsou možné nebo by vyžadovaly velmi komplikované výpočty standardních chyb (jako v případě intervalů spolehlivosti pro medián, kvartily a další percentily).
V IBM SPSS Statistics 27 jsou bootstrapové odhady k dispozici pro tyto procedury ze základního modulu Base: Frequencies, Descriptives, Explore, Crosstabs, Means, One-Sample T Test, Independent-Samples T Test, Paired-Samples T Test, One-Way ANOVA, GLM Univariate, Bivariate Correlations, Partial Correlations, Linear Regression, Ordinal Regression, Discriminant Analysis a dále procedury z modelu Advanced Statistics: GLM Multivariate, Linear Mixed Models, Generalized Linear Modelsa Cox Regression a z modulu Regression: Binary Logistic Regression a Multinomial Logistic Regression.
Způsob zadávání
Zadávání je u většiny procedur obdobné. Ukažme si to na příkladu procedury Frequencies v nabídce Analyze, Descriptive Statistics, Frequencies, kterou využijeme pro odhad popisných statistik proměnné Současný plat. Jedná se o platy zaměstnanců z určité společnosti. Vybrané statistiky (průměr, směrodatná odchylka, minimum, maximum, medián, dolní a horní kvartil) označíme pod tlačítkem Options a zároveň zrušíme zobrazování tabulky četností (zaškrtávací políčko Display frequency tables v hlavním dialogu). Pomocí tlačítka Bootstrap zadáme výpočet robustních odhadů standardních chyb a intervalů spolehlivosti pro popisné statistiky, u nichž mají intervaly spolehlivosti smysl.
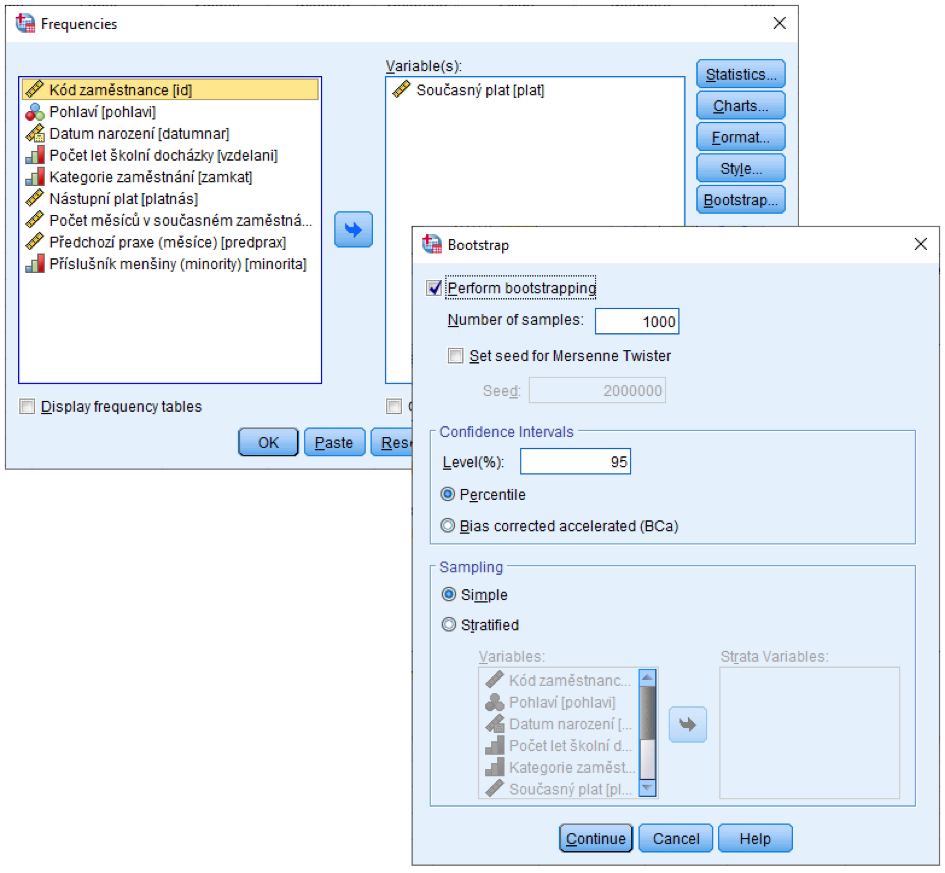
V dialogu tlačítka Bootstrap označíme Perform bootstrapping a určíme počet bootstrapových výběrů (Number of samples). Defaultně je nastavena hodnota 1000.
Zaškrtávací políčko Set seed for Mersenne Twister umožňuje zadat počáteční hodnotu pro generátor náhodných čísel (Seed). To může být užitečné, pokud bychom potřebovali výsledek později přesně zreplikovat (výsledek je založený na náhodných číslech a jinak se může při opakování nepatrně lišit).
V části Confidence Intervals zadáme hladinu spolehlivosti (Level(%)) a zvolíme metodu výpočtu intervalu spolehlivosti (Percentile nebo Bias corrected accelerated (BCa)).
V části Sampling určíme, zda se mají bootstrapové výběry realizovat z celého souboru (Simple), nebo v rámci strat (Stratified) a do pole Strata Variables případně zadáme stratifikační proměnné.
Výstupy
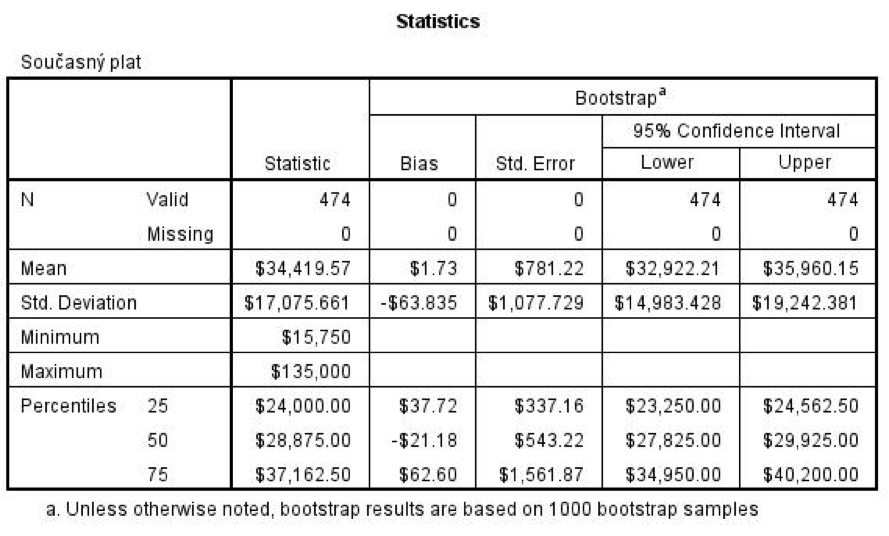
Následně se ve výstupu zobrazí tabulka, která obsahuje kromě standardních odhadů jednotlivých statistik (Statistic) rovněž bootstrapové odhady (Bootstrap): vychýlení (Bias), tj. rozdíl mezi odhadem statistiky na základě bootstrapových výběrů a standardním odhadem z originálního souboru, standardní chybu (Std. Error) a interval spolehlivosti (95 % Confidence Interval).
Pro minimum a maximum nemají odhady standardních chyb ani intervalů spolehlivosti smysl, proto se nezobrazují.
Na závěr si ještě zodpovíme otázku, která se skrývá v nadpise článku. Slovem bootstraps se v angličtině označují řemínky, které mají některé typy vyšších bot a mohou se užít například pro jejich snazší zvednutí. Název bootstrapping vychází z fráze “Pull yourself up by your bootstraps”, která by se dala volně přeložit jako „zvednout sám sebe na řemíncích od svých bot“. Původní význam této metafory odkazoval na něco absurdního nebo nemožného, aktuálně se však užívá spíše pro vyjádření úspěchu při zlepšení situace bez cizí pomoci. Tato metafora velmi dobře charakterizuje metodu bootstrapping.
Rádi byste se o statistice a analýze dat dozvěděli více? Chcete se stát mistrem ve svém oboru nebo si jen potřebujete doplnit znalosti? V ACREA nabízíme širokou nabídku kurzů pro váš profesní růst. Máte-li jiný dotaz. Nebojte se využít naši nezávaznou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení.


Asi by se mělo doplnit, že pokud v uvedeném příkladu byly údaje o platech zaměstnanců z určité společnosti a nebyla to výběrová data, ale bylo to úplné zjišťování, pak bootstrapping (a intervaly spolehlivosti), nemá smysl.
Máte samozřejmě pravdu, že je nutné pracovat s výběrovými daty, aby mělo smysl vyjadřovat intervaly spolehlivosti. V tomto příkladě jsem pro jednoduchost použila ukázková data z IBM SPSS Statistics, a přesněji jsem měla napsat, že se jedná o (náhodný) výběr zaměstnanců z určité společnosti/oboru.