V mnoha oblastech datové analýzy se setkáváme s daty, která nejsou zcela nezávislá. Žáci jsou součástí tříd, zaměstnanci pracují ve firmách nebo jsou hodnoty měřeny opakovaně na jednom pacientovi. Tradiční lineární modely často tyto struktury a závislosti ignorují. Pokud bychom jejich výsledky analyzovali běžnými...
Celý článek
Statistika nabízí celou řadu metod, jak ověřit naše hypotézy a rozhodnout, zda rozdíly mezi skupinami či měřeními mají skutečný význam. Jednou z nejčastěji používaných metod je t-test, který se uplatňuje v přírodních vědách, medicíně, vzdělávání, průmyslu i v sociálních vědách. Tento článek se zaměřuje na vysvětlení, co t-test...
Celý článek
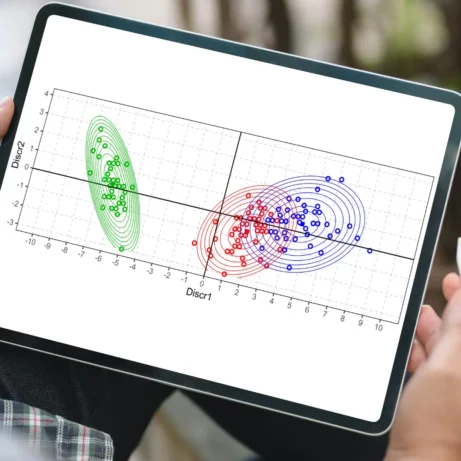
V minulé části jsme si ukázali, jak se v diskriminační analýze provádí klasifikace do skupin. Používají se dva, co se výsledku týče, ekvivalentní způsoby, kdy jeden pracuje s diskriminačními funkcemi a druhý s funkcemi klasifikačními. Nyní přikročíme k srovnání klasifikace s další široce rozšířenou metodou pro klasifikaci, tedy s logistickou regresí. Logistická regrese...
Celý článek
Klasifikace v lineární diskriminační analýze V minulé části jsme se seznámili se vzorcem pro výpočet aposteriorní pravděpodobnosti (1) založeném na Mahalanobisovově vzdálenosti (2) a zmínili jsme, že vzorec se výrazně zjednoduší v případě lineární diskriminační analýze (dále DA). Vzorec se týká kanonických diskriminačních funkcí, které jsou...
Celý článek
Jednou z velmi častých úloh statistiky i datascience je klasifikace. Úloha spočívá v odhadu skupiny (třídy), ke které případ náleží na základně jeho vlastností zachycených sadou číselných i kategorizovaných proměnných. Ty budeme nazývat vysvětlující. V úloze se například určuje diagnóza pacienta podle výsledků vyšetření nebo budoucí platební morálka...
Celý článek