ACREA TEXT MINING
- nástroj pro analýzu textu v českém a slovenském jazyce
Objevte nadstavbový modul dataminingového softwaru IBM SPSS Modeler, který dokáže nestrukturovaná data převést do strukturované podoby vhodné pro další strojové zpracování. Modul umožňuje nejen klasifikovat, seskupovat či jinak zpracovávat textové dokumenty, ale také využít informaci ukrytou v českém či slovenském textu pro zdokonalení vašich predikčních modelů.
Online ukázka softwaru zdarma
Jedna online schůzka vám ušetří hodiny času i hledání informací

Dozvíte se:
- jak software funguje v praxi
- jak vám pomůže při zpracování dokumentů
- s jakými úlohami analýzy textu se často setkáváme
... a to vše nezávazně a přehledně
Uzly ACREA Text Mining
Termíny
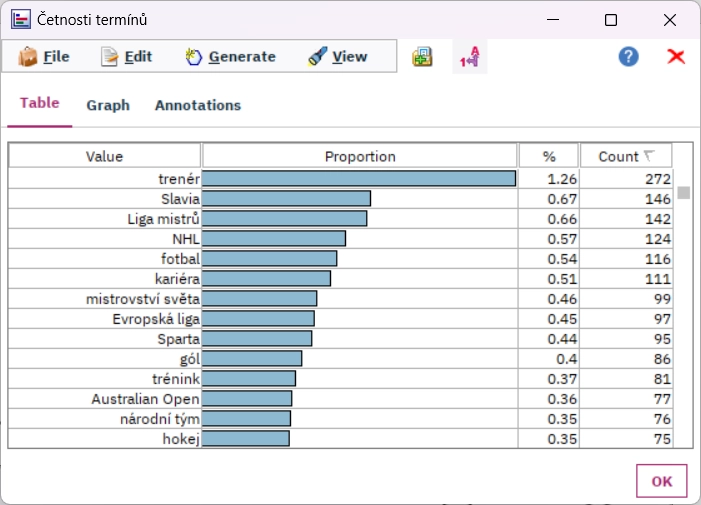
Extrahujte klíčová slova a sousloví z volných textů. Nalezené termíny se stanou základem pro analýzu obsahu a všechny predikční textminingové úlohy. Extrahovaná slova a sousloví jsou v základním tvaru (1. pád jednotného čísla nebo infinitiv). Důležitost termínu pro každý dokument je možné číselně kvantifikovat.
Sentiment
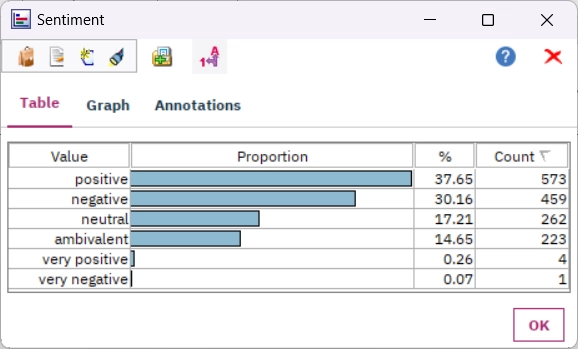
Získejte sentiment z komentářů, mailů, přepisů telefonních hovorů nebo recenzí vašich zákazníků. Procedura ohodnotí každý dokument dle postoje autora. Nejenže se každý dokument zařadí do pozitivní, negativní, neutrální či ambivalentní kategorie, ale k dispozici jsou i číselné kvantifikace pozitivního a negativního vyznění dokumentu.
Pojmenované entity
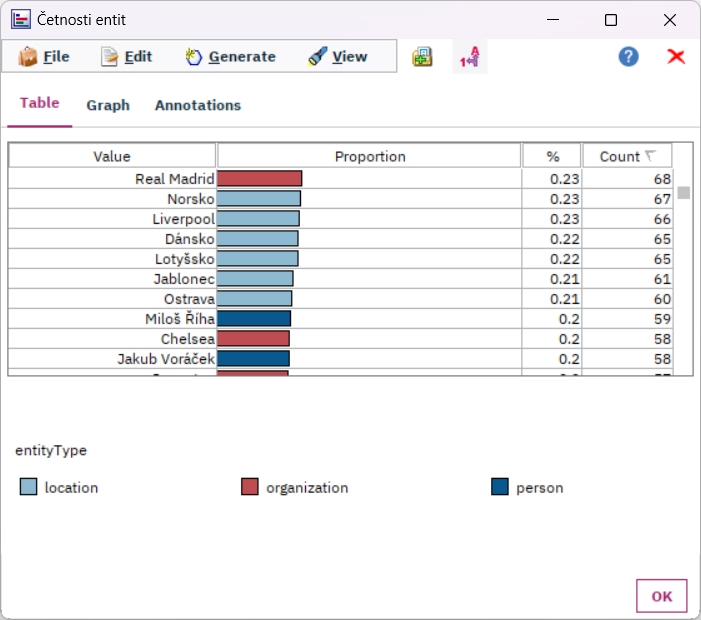
Najděte v textech všechna jména osob, firem a lokalit. Nalezené pojmenované entity jsou v základním tvaru (1. pád jednotného čísla). Z pojmenovaných entit můžete vytvořit vztahové mapy, přiřadit jim sentiment nebo je prostě využít jako prediktory v textminingových úlohách.
Textové soubory
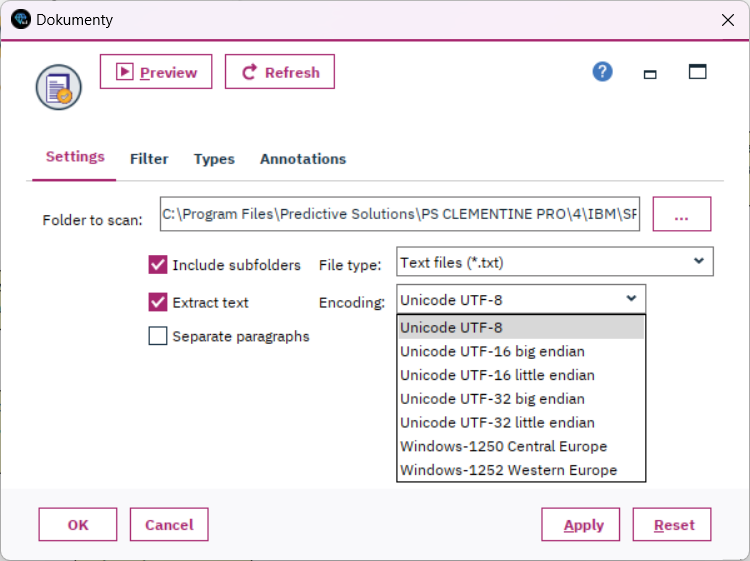
Naplňte datovou matici texty uloženými v mnoha textových souborech. Díky podpoře běžných typů kódování češtiny a slovenštiny máte jistotu, že písmena s diakritikou se správně načtou. A pokud jsou dokumenty dlouhé, je možné je před analýzou rozdělit na odstavce a ty zpracovávat odděleně.
Regulární výrazy

Vyhledávejte v dokumentech URL, čísla dokladů, e-maily, finanční částky nebo jen rozdělte text na slova. Regulární výrazy obsahují speciální zástupné znaky, které je možno ztotožnit s mnoha konkrétními znaky v textu. Pokud neznáte syntaxi, použijte implementovanou kalkulačku pro intuitivní psaní regulárních výrazů.
Editační vzdálenost
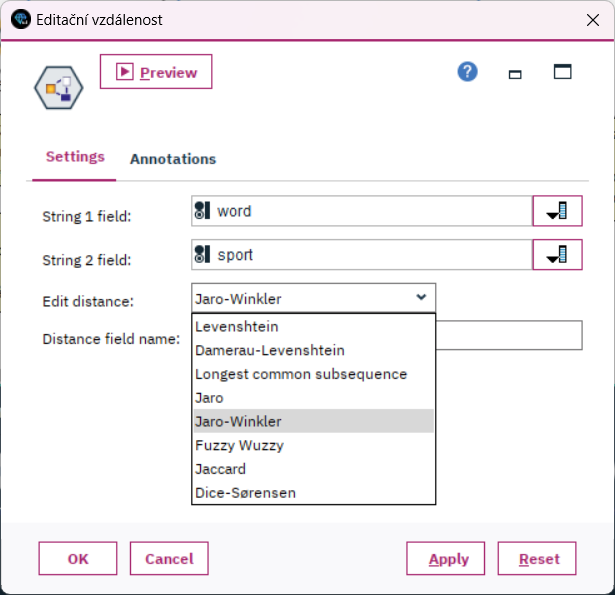
Zkoumejte, jak jsou si texty podobné. Může se jednat jen o hledání morfologických tvarů daného slova nebo překlepů, ale lze porovnávat i podobnost celých článků a jiných autorských prací. Na měření podobnosti si můžete vybrat jakoukoli z běžně používaných editačních vzdáleností.
Oblak slov
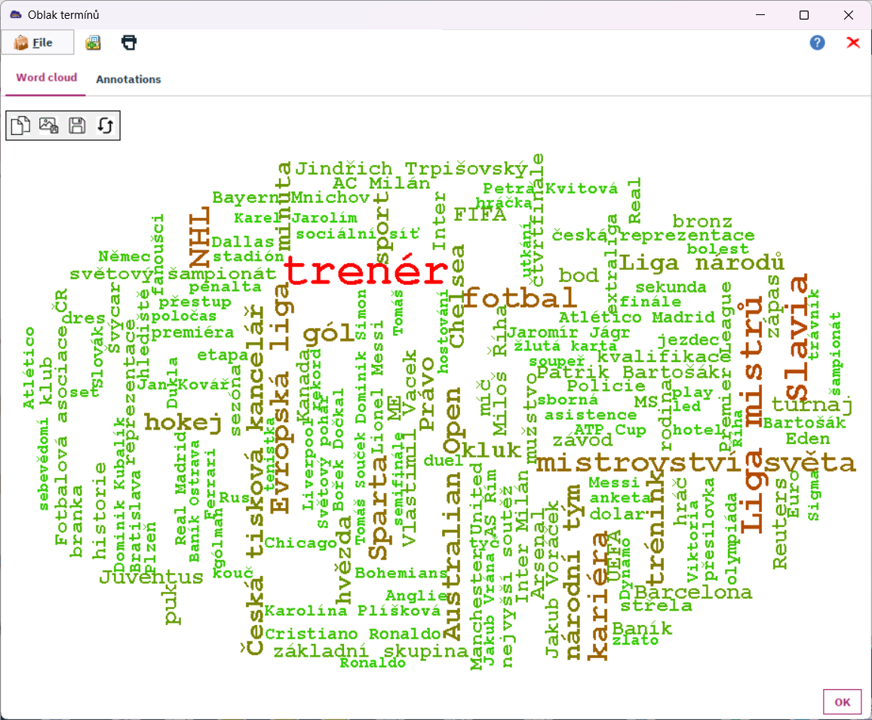
Nakreslete si obrázek s důležitými termíny, pojmenovanými entitami či s výsledky hledání. Lépe se prezentuje než četnostní tabulky. U oblaku slov si můžete vybrat z několika tvarů a různou velikostí písma podle četnosti výskytu. Pokud vám nevyhovuje rozmístění slov v oblaku, nechte ho překreslit nebo jednoduše změňte velikost okna.
Náhled na dokumenty
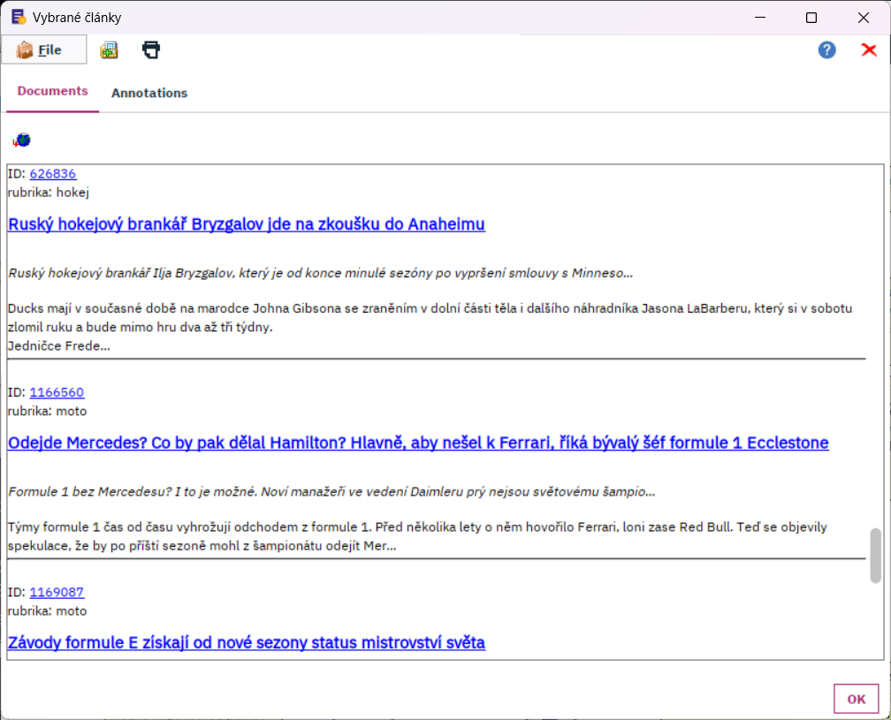
Získejte kompaktní náhled na texty z kolekce zpracovávaných dokumentů. Zobrazené úryvky (snippets) umožní lepší orientaci v dokumentech než zobrazení v datové matici. Navíc je možné u každého dokumentu zobrazit celou řadu metadat jako jsou autor, sentiment nebo zdroj článku. K nadpisům a vybraným metadatům můžete přiřadit hypertextové odkazy.
Úlohy ACREA Text Mining a IBM SPSS Modeler
Analýza obsahu
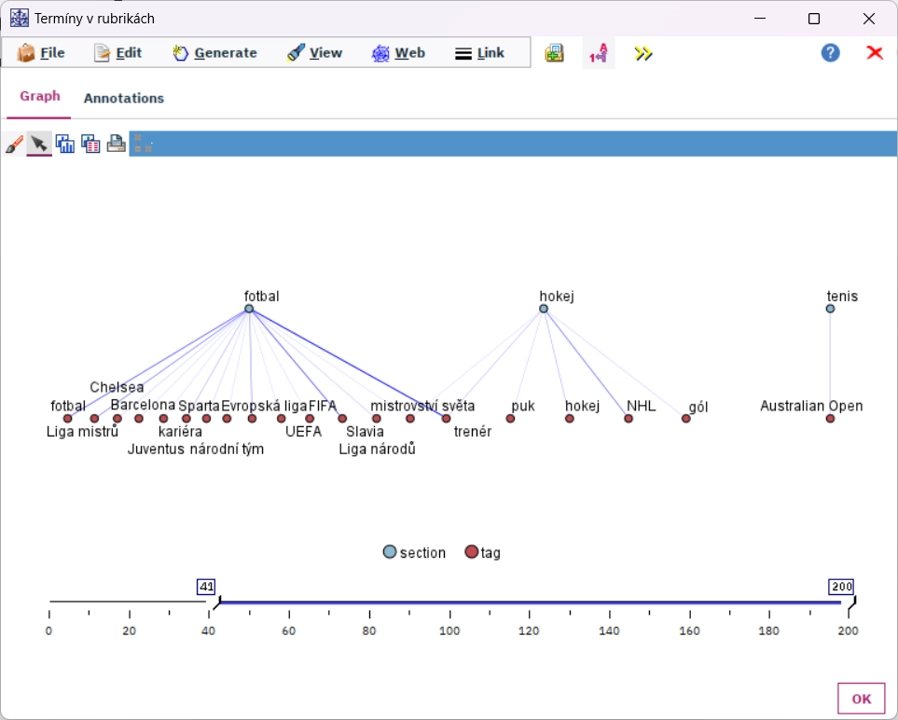
Neztrácejte čas čtením velkého množství dokumentů. Nechte si z nich vyextrahovat důležité termíny, osoby, firmy a lokality a případně i zjistěte jejich sentiment. Výsledky lze snadno vizualizovat grafickými nástroji IBM SPSS Modeler a získat tak rychlý přehled o tématech, o kterých se v dokumentech píše. Reportovat můžete třeba i časový vývoj jednotlivých témat.
Vyhledávání
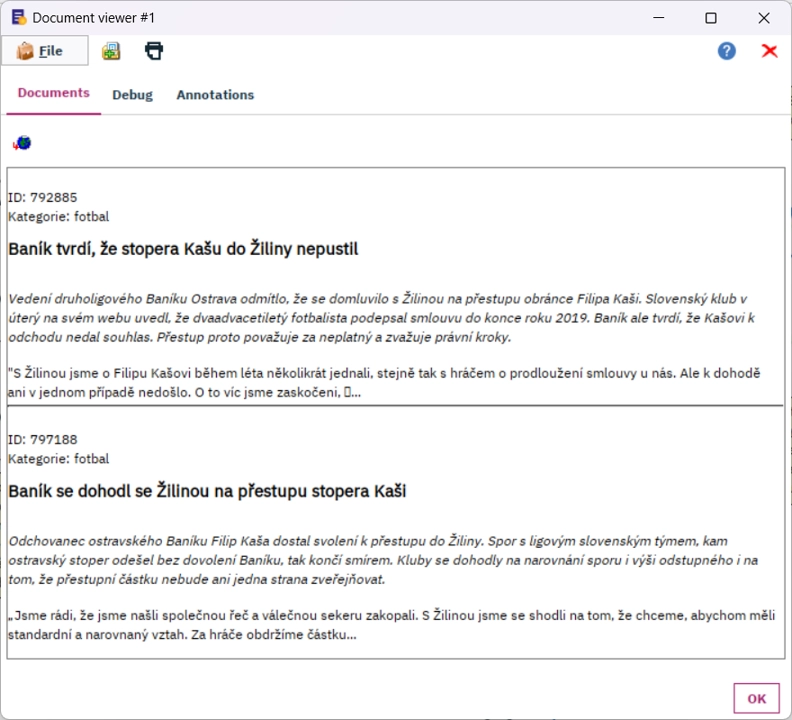
Potřebujete k jednomu dokumentu ve velké kolekci dokumentů najít ty nejpodobnější? Reprezentujte všechny dokumenty pomocí klíčových slov nebo pojmenovaných entit a spočtěte si jejich podobnost. Podle spočtené podobnosti můžete výsledky řadit nebo filtrovat.
Klasifikace
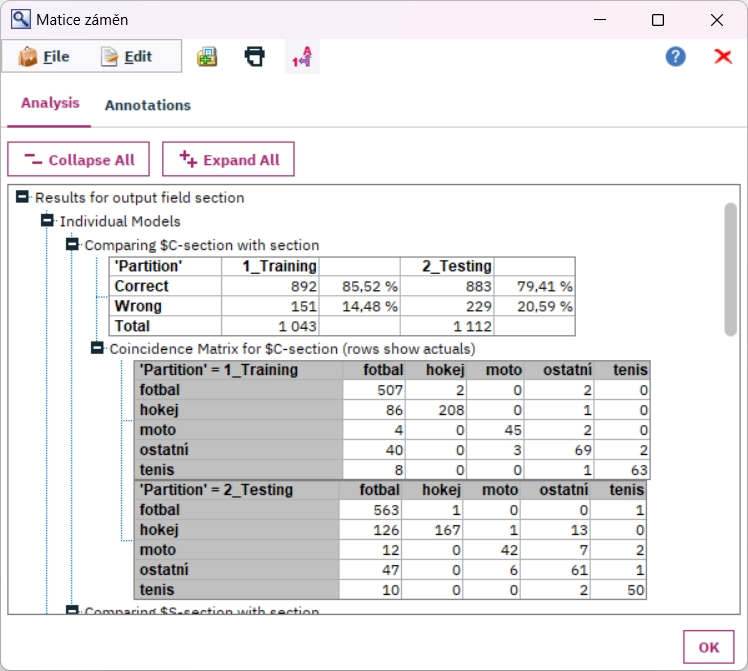
Klasifikační model roztřídí velké množství textových dokumentů do předem známých kategorií. Dokumenty lze roztřídit na základě klíčových slov, pojmenovaných entit či jiných atributů extrahovaných z volného textu. Při vybírání optimálního klasifikačního algoritmu si můžete vybrat z pestré škály modelů, které nabízí IBM SPSS Modeler.
Seskupování
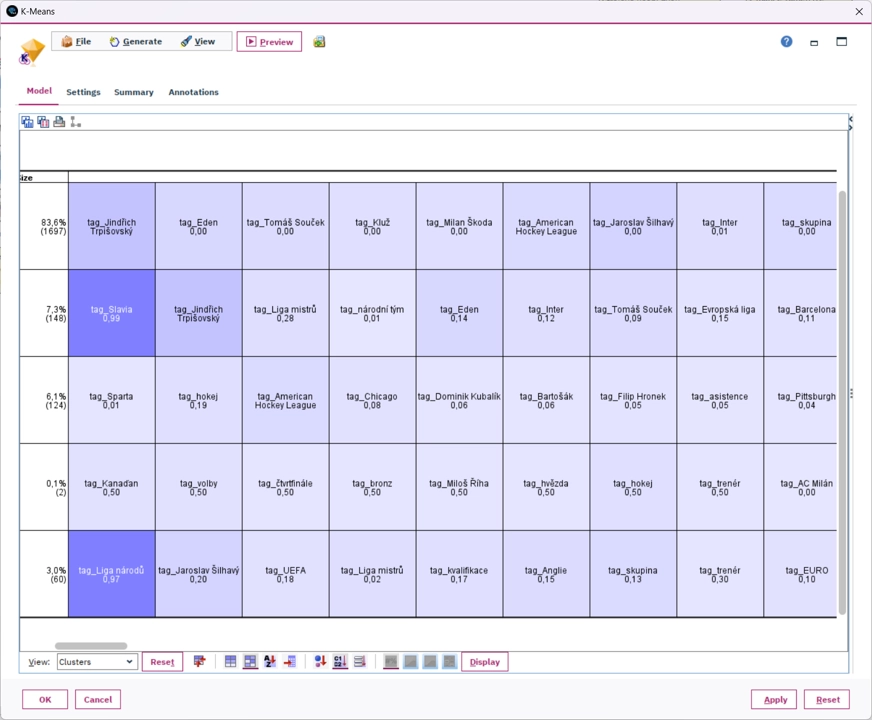
Chcete otevřené odpovědi, došlé emaily nebo recenze roztřídit do zatím neznámých skupin tak, aby si dokumenty ve skupině byly podobné? Extrahujete z dokumentů klíčová slova, pojmenované entity či sentiment a vyberte si z pestré škály seskupovacích procedur IBM SPSS Modeler nejvhodnější algoritmus. Interaktivní výstupy vám pomohou vybrat nejlepší řešení a interpretovat zaměření nalezených skupin.
Další možnosti softwaru
Plná integrace modulu do softwaru IBM SPSS Modeler umožňuje zařazení jednotlivých textminingových uzlů do proudů pro přípravu dat, jejich analýzu, modelování a predikce. Obohacuje tak možnosti analýzy strukturovaných dat o nové informace z dat nestrukturovaných, které mohou zkvalitnit výsledné modely.
Podpora češtiny a slovenštiny
Integrace do IBM SPSS Modeleru
Skórování
Rozpoznání jazyka
Diakritizace
VYUŽITÍ TEXT MININGU V PRAXI
Vyberte si z typických úloh, které lze pomocí softwaru IBM SPSS Modeler s modulem ACREA Text Mining a se zkušenostmi analytiků ACREA řešit.