Vyhledávání pomocí regulárního výrazu
uzel Regular Expression
Uzel Regular Expression hledá v textovém dokumentu všechny řetězce vyhovující regulárnímu výrazu. Volitelně lze do datové matice přidat pozice nalezených řetězců v dokumentu.
Pro psaní a syntaktickou kontrolu regulárních výrazů je možné použít kalkulačku. Kalkulačka umožňuje do výrazů vkládat nejpoužívanější speciální znaky. Po stisknutí tlačítka Check se vkládaný výraz v kalkulačce obarví zeleně, pokud je zapsán syntakticky správně. Chybný výraz se obarví červeně.
Uzel Regular expression restrukturalizuje datovou matici na dlouhý formát, kde řádky reprezentují nalezené řetězce. Jeden dokument je v dlouhém formátu reprezentován více řádky sdílejícími stejný identifikátor dokumentu.
záložka Settings
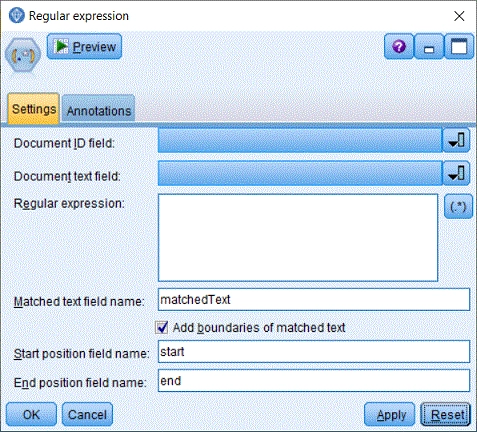
- Document ID fieldAtribut s jednoznačnou identifikací dokumentu. Může být textový nebo celočíselný.
- Document text fieldTextový atribut obsahující text dokumentu.
- Regular ExpressionHledaný regulární výraz. Výraz lze zapsat z klávesnice nebo stisknout tlačítko (.*) a využít k psaní kalkulačku regulárních výrazů.
- Matched text field nameJméno nového atributu s nalezenými řetězci.
- Add boundaries of matched textPřipojení atributů s pozicí nalezeného řetězce. K datové matici se připojí atributy s počáteční a koncovou pozicí.
- Start position field nameJméno nového atributu s pozicí prvního znaku nalezeného řetězce.
- End position field nameJméno nového atributu s pozicí posledního znaku nalezeného řetězce.