Sémantické značkování dokumentů
uzel Labels
Uzel Labels extrahuje z textového dokumentu termíny charakterizující obsah dokumentu. Termíny obsahují klíčová slova a pojmenované entity. Typy termínů je možné zaznamenat do datové matice jako nový atribut s hodnotami KEYWORDS a ENTITIES. Volitelně lze ke každému termínu přiřadit číselné skóre úměrné četnosti a poloze termínu v dokumentu. Před extrakci termínů lze předřadit automatické rozpoznání jazyka a diakritizaci dokumentů psaných bez diakritiky.
Uzel Labels restrukturalizuje datovou matici na dlouhý formát, kde řádky reprezentují jednotlivé nalezené termíny. Jeden dokument je v dlouhém formátu reprezentován více řádky sdílejícími stejný identifikátor dokumentu. Dlouhý formát umožní snadněji s termíny manipulovat. Pro modelování je vhodné vybrané termíny transformovat na široký formát pomocí uzlu Restructure nebo SetToFlag.
záložka Settings
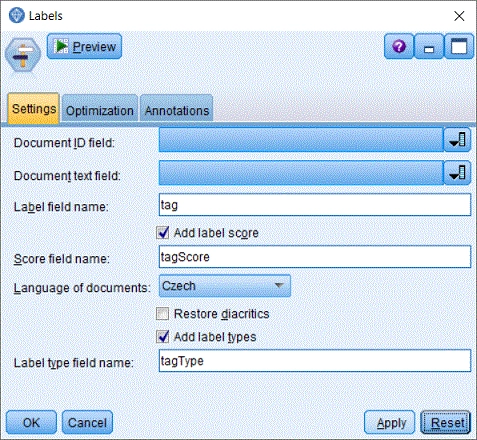
- Document ID fieldAtribut s jednoznačnou identifikací dokumentu. Může být textový nebo celočíselný.
- Document text fieldTextový atribut obsahující text dokumentu.
- Label field nameJméno nového atributu s extrahovanými termíny.
- Add label scoresPřipojení skóre termínu do nového atributu.
- Score field nameJméno nového atributu s číselným skóre termínů.
- Language of documentsJazyk dokumentů. Na výběr je čeština (Czech), slovenština (Slovak) a automatická detekce jazyka (Automatic detection).
- Restore diacriticsAutomatická diakritizace dokumentů neobsahujících diakritiku. Diakritizace se provede před extrakcí termínů.
- Add label typesPřipojení typu termínu do nového atributu.
- Label type field nameJméno nového atributu s typem termínu.
záložka Optimization
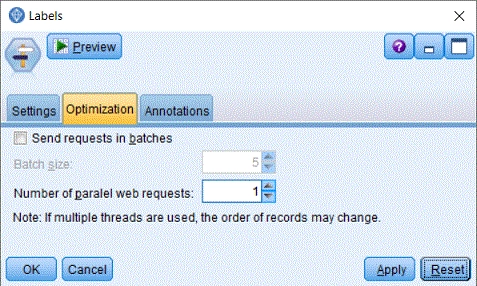
- Send requests in batchesDávkové zasílání dokumentů na server.
- Batch sizePočet dokumentů v dávce.
- Number of paralel web requestsPočet paralelních vláken pro zpracování dokumentů. Vlákna pracují na sobě nezávisle, proto se pořadí dokumentů na výstupu může lišit od pořadí na vstupu.