Klasifikace sentimentu
uzel Sentiment
Uzel Sentiment přiřadí textovému dokumentu kategorii sentimentu a volitelně kvantifikuje sentiment v dokumentu pomocí skóre. Před samotnou kategorizací lze předřadit automatické rozpoznání jazyka a diakritizaci dokumentů psaných bez diakritiky.
Kategorie sentimentu jsou very negative, negative, neutral, positive, very positive, ambivalent. Celkové skóre nabývá hodnot od -1 do +1. Kladné hodnoty indikují pozitivní sentiment, záporné negativní. Celkové skóre je součtem pozitivního a negativního skóre. Zvolíte-li automatickou detekci jazyka, jazyk dokumentu se připojí do datové matice jako nový atribut.
záložka Settings
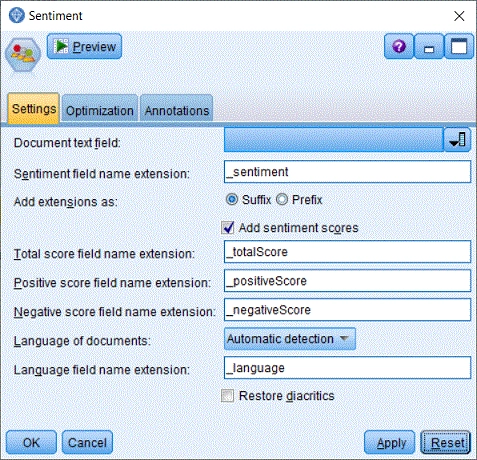
- Document text fieldTextový atribut obsahující text dokumentu.
- Sentiment field name extensionPředpona nebo přípona nového atributu s kategorií sentimentu.
- Add extensions asPřidané atributy se pojmenovávají jako atribut s textem dokumentu a ke jménu se přidávají předpony nebo přípony. Pro používání předpon zvolte prefix, pro používání přípon zvolte suffix.
- Add sentiment scoresVytvoření nových atributů obsahujících číselná skóre sentimentu. K datové matici se připojí atributy s celkovým skóre, s pozitivním skóre a s negativním skóre.
- Total score field name extensionPředpona nebo přípona nového atributu s celkovým skóre.
- Positive score field name extensionPředpona nebo přípona nového atributu s pozitivním skóre.
- Negative score field name extensionPředpona nebo přípona nového atributu s negativním skóre.
- Language of documentsJazyk dokumentů. Na výběr je čeština (Czech), slovenština (Slovak) a automatická detekce jazyka (Automatic detection). Při automatické detekci jazyka se rozpoznaný jazyk zaznamená do nového atributu.
- Language field name extensionPředpona nebo přípona nového atributu s automaticky rozpoznaným jazykem.
- Restore diacriticsAutomatická diakritizace dokumentů neobsahujících diakritiku. Diakritizace se provede před analýzou sentimentu.
záložka Optimization
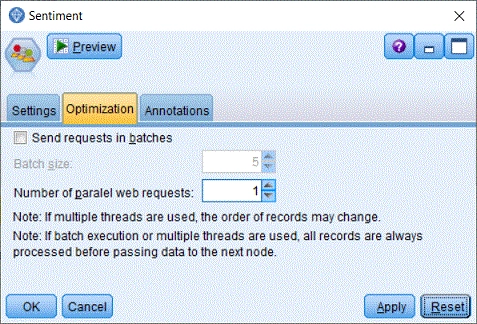
- Send requests in batchesDávkové zasílání dokumentů na server.
- Batch sizePočet dokumentů v dávce.
- Number of paralel web requestsPočet paralelních vláken pro zpracování dokumentů. Vlákna pracují na sobě nezávisle, proto se pořadí dokumentů na výstupu může lišit od pořadí na vstupu.