Znaménkové schéma – binomický test
SPRIPT K SOFTWARU IBM SPSS STATISTICS
Skript zpivotuje vstupní kontingenční tabulku a nahradí adjustovaná rezidua znaménkovým schématem.
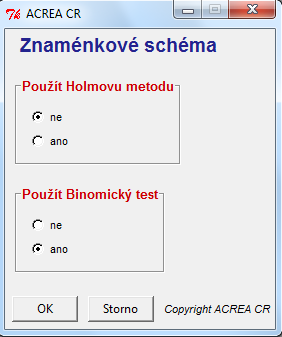
MOŽNOSTI
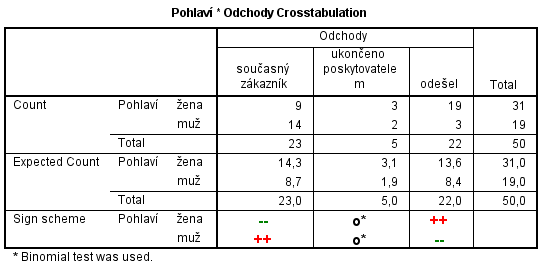
Skript spustíte v nabídce Utilities -> Run Script. Skript zpivotuje vstupní kontingenční tabulku a nahradí adjustovaná rezidua znaménkovým schématem. Znaménkové schéma opticky zvýrazní buňky, jejichž četnost se významně liší od očekávané četnosti za předpokladu nezávislosti sledovaných znaků. Typ znaménka reprezentuje směr odchylky:
- neliší-li se naměřená četnost významně od očekávané, v buňce se objeví znaménko "o",
- vyšší naměřené četnosti oproti očekávání se označí znaménkem "+",
- nižší naměřené četnosti oproti očekávání se naopak zvýrazní znaménkem "-".
V každé buňce se mohou vyskytnout jedno až tři znaménka plus nebo mínus podle statistické významnosti odchylky – jedno znaménko při 95% významnosti, dvě při 99% a tři při 99,9% významnosti.
Je-li požadováno simultánní testování, lze v úvodním dialogu zvolit použití Holmovy sekvenční metody, která zajistí dodržení požadované hladiny významnosti pro všechny testované buňky dohromady.
V úvodním dialogu lze zvolit použití binomického testu. Tato volba zabezpečí, že v případě, že jsou očekávané četnosti menší než 5, bude ke konstrukci znaménkového schématu v dané buňce využit binomický test.
UKÁZKA VÝSTUPU
Výstupem je zpivotovaná vstupní kontingenční tabulka s nahrazenými adjustovanými reziduy znaménkovým schématem.
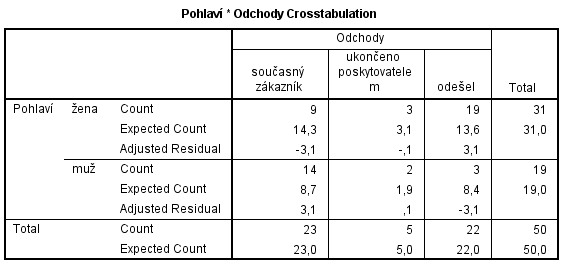
Tabulka před použitím skriptu
Tabulka po použití skriptu
PŘEDPOKLADY POUŽITÍ
Skript nelze provozovat bez softwaru IBM SPSS Statistics s modulem Base a propojení s programovacím jazykem Python.
Jedna nebo více kontingenčních tabulek vytvořených procedurou Analyze -> Descriptive Statistics -> Crosstabs obsahujících adjustovaná rezidua, pozorované a očekávané četnosti.
- Před spuštěním skriptu je nutné označit aspoň jednu kontingenční tabulku (jednoduchý rámeček).
- Tabulka nesmí být před použitím skriptu upravována.
- Tabulka musí obsahovat adjustovaná rezidua, pozorované a očekávané četnosti (v proceduře Crosstabs pod tlačítkem Cells označit Adj. Standardized, Observed a Expected).