Co je nového ve verzi IBM SPSS Statistics 27

Verze IBM SPSS Statistics 27 přináší celou řadu novinek a vylepšení. Většina z nich se týká základního modulu Base, některé změny se ale vztahují i k dalším modulům. Tento článek nabízí přehled nejdůležitějších novinek, v dalších navazujících článcích se potom zaměříme na některé z nich detailněji.
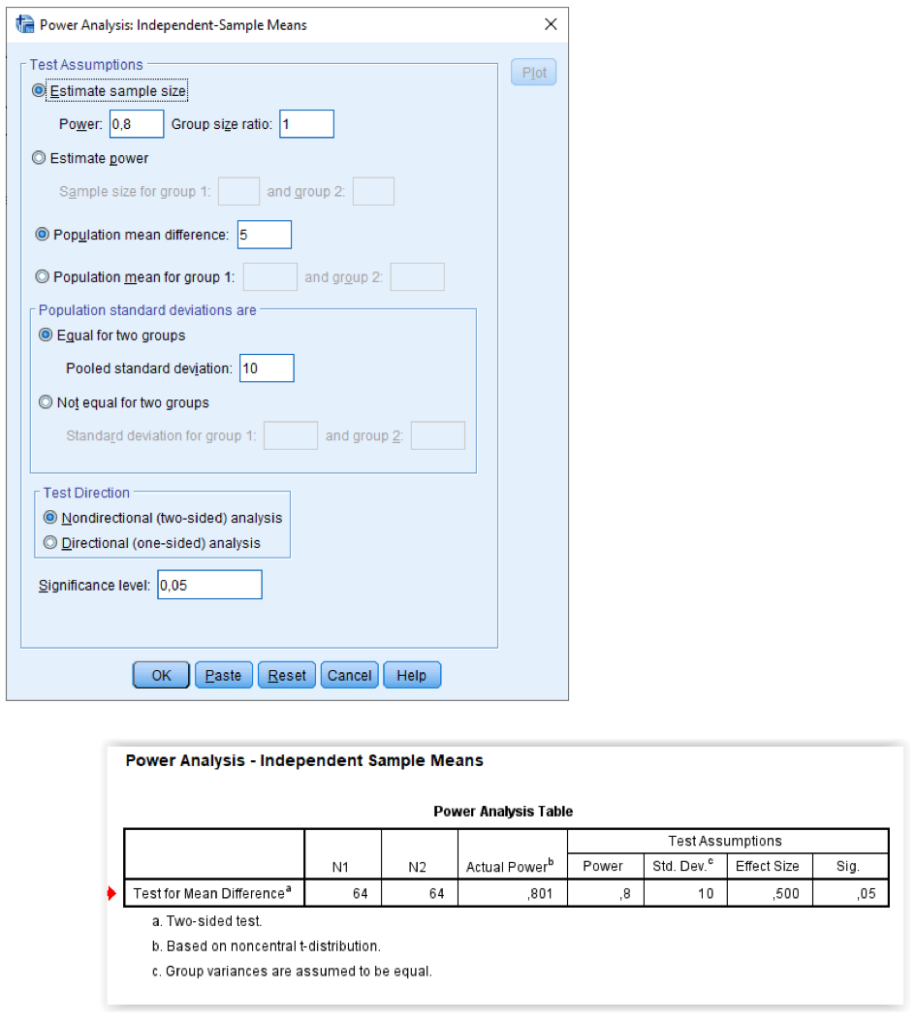
Power analýza
Mezi hlavní novinky verze 27 patří procedury umožňující provádět analýzu síly testu (power analýzu). Naleznete je pod nabídkou Analyze, Power Analysis a jsou k dispozici pro řadu běžně užívaných statistických testů (T-testy, analýza rozptylu, testy proporcí, testy hypotéz o korelačních koeficientech, testy nulovosti parametrů v lineární regresi).
Síla testu (power) je jednou ze základních vlastností statistických testů. Je to pravděpodobnost, že statistický test správně zamítne nulovou hypotézu, pokud neplatí. Čím je test silnější, tím spíše odhalí i malou odchylku od nulové hypotézy.
Analýza síly testu hraje klíčovou roli při plánování výzkumů. Nejčastěji se užívá k určení optimální velikosti výběrového souboru. Pokud je výběrový soubor příliš malý, test nemusí být schopen odhalit ani výraznou odchylku od nulové hypotézy. Naopak zbytečně velký soubor znamená vyšší náklady, ale také může snadno vést k přeceňování statistické významnosti. I v případě analýzy dat, u nichž není možné počet pozorování předem ovlivnit, je dobré vědět, s jakou sílou je statistický test schopen odhalit odchylku, která je již věcně významná.
Procedury pro přípravu dat nově zařazené v modulu Base
Další zásadní změny se týkají modulů a licencování. Ve verzi IBM SPSS Statistics 27 byl nově zařazen původní modul Data Preparation do základního modulu Base. Všichni uživatelé, kteří mají alespoň základní modul Base, nyní mohou využívat řadu velmi užitečných procedur pro přípravu dat, aniž by si museli dokupovat další modul:
- Nabídka Data, Validationje určena ke kontrole a ověření kvality dat. Umožňuje nahrát předdefinovaná pravidla pro kontrolu dat (Load Predefined Rules), definovat vlastní pravidla (Define Rules) a provést validaci dat (Validate Data).
- Procedura Identify Unusual Cases umožňuje identifikovat neobvyklé případy na základě seskupení případů do klastrů a jejich vzdálenosti ke středu nejbližšího klastru. Algoritmus přitom využívá metodu TwoStep Cluster. Naleznete ji v nabídce Data, Identify Unusual Cases.
- Procedura Optimal Binning v nabídce Transform je určená k optimální kategorizaci jedné nebo více číselných proměnných vzhledem k dané kategorizované proměnné. Nově odvozenou kategorizovanou proměnnou (proměnné) lze následně užít pro další analýzu. Algoritmus je založený na metodě MDLP (minimal description length principle) a na statistice Entropie.
- Nabídka Transform, Prepare Data for Modeling je určená k přípravě dat pro modelování. Její součástí je interaktivní příprava dat (Interactive), automatická příprava dat (Automatic) a možnost zpětné transformace předpovídaných hodnot cílové proměnné na základě modelu v případě, že pro přípravu dat byla užita jedna z těchto dvou procedur (Backtransform Scores).
Bootstrapping nově v modulu Base
Dalším modulem, jehož nástroje jsou nově zařazeny do základního modulu Base je Bootstrapping. V tomto případě nejsou k dispozici další procedury, avšak řada standardních statistických procedur obsahuje tlačítko Bootstrap, pomocí něhož lze zadat výpočet robustních odhadů standardních chyb a intervalů spolehlivosti na základě metody bootstrap pro odhady statistik jako například průměr, medián, proporce, podíl šancí, korelační koeficient nebo regresní koeficienty.
Jedná se o tyto procedury ze základního modulu Base: Frequencies, Descriptives, Explore, Crosstabs, Means, One-Sample T Test, Independent-Samples T Test, Paired-Samples T Test, One-Way ANOVA, GLM Univariate, Bivariate Correlations, Partial Correlations, Linear Regression, Ordinal Regression, Discriminant Analysisa dále procedury z modelu Advanced Statistics: GLM Multivariate, Linear Mixed Models, Generalized Linear Modelsa Cox Regression a z modulu Regression: Binary Logistic Regressiona Multinomial Logistic Regression.
Cohenovo vážené kappa
V nabídce Analyze, Scale, Weighted Kappa naleznete novou proceduru určenou pro výpočet Cohenova váženého kappa. Cohenovo kappa vyjadřuje míru shody dvou kategorizovaných proměnných s identickými kategoriemi, přičemž bere v úvahu i možnost náhodné shody. Užívá se například pro posouzení shody dvou hodnotitelů při klasifikaci subjektů do několika skupin. Výpočet vychází ze čtvercové kontingenční tabulky.
Neváženou variantu Cohenova kappa, určenou především pro nominální proměnné, nabízí procedura Crosstabs. Cohenovo vážené kappa navíc zohledňuje skutečnost, že záměna některých dvojic kategorií je závažnější než záměna jiných, což je charakteristické například pro ordinální proměnné. Procedura nabízí odhad této statistiky založený na předdefinovaných vahách polí kontingenční tabulky (lineární nebo kvadratické). Vstupní proměnné mohou být numerické nebo textové. Odhad váženého Cohenova kappa má smysl pouze v případě, že kategorie proměnných jsou odpovídajícím způsobem seřazené – u numerických proměnných se vychází z pořadí číselných hodnot, u textových z uspořádání podle abecedy. Součástí výstupu jsou rovněž intervaly spolehlivosti, test nulovosti a další.
Další statistická vylepšení
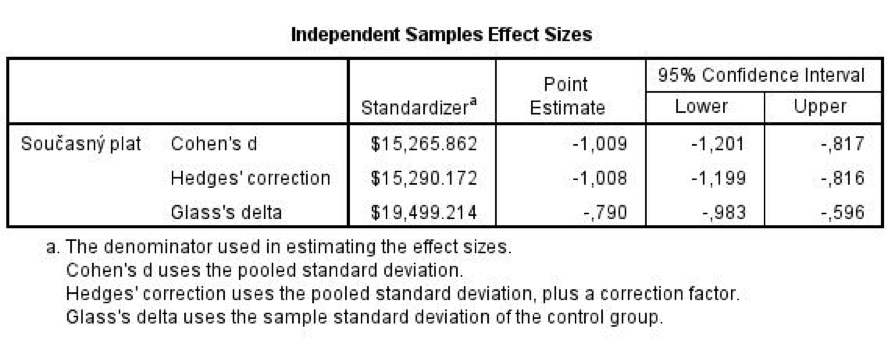
Rozšířeny byly rovněž procedury pro T-testy a analýzu rozptylu (v nabídce Analyze, Compare Means: One-Sample T tests, Independent-Samples T tests, Paired-Samples T tests a One-Way ANOVA). Nově nabízejí také odhady effect size, a to včetně kontrastů v analýze rozptylu.
Vylepšena byla i procedura pro kvantilovou regresi (nabídka Analyze, Regression, Quantile), která je součástí modulu Regression. Pod tlačítkem Criteria nyní nabízí uživatelsky příjemnější způsob zadávání kvantilů, což je užitečné zvláště při specifikaci většího počtu hodnot.
Pokročilejší uživatelé ocení rozšíření syntaxového příkazu MATRIX-END MATRIX, který nyní při práci s maticemi umožňuje využívat řadu nových funkcí (funkce pravděpodobnostních rozdělení, funkce pro generování pseudonáhodných hodnot, funkce pro výpočet dosažené hladiny významnosti (signifikance) chí-kvadrát rozložení a F-rozložení a další). Změny a rozšíření se však týkají i mnoha dalších syntaxových příkazů.
Vylepšení práce s výstupy:
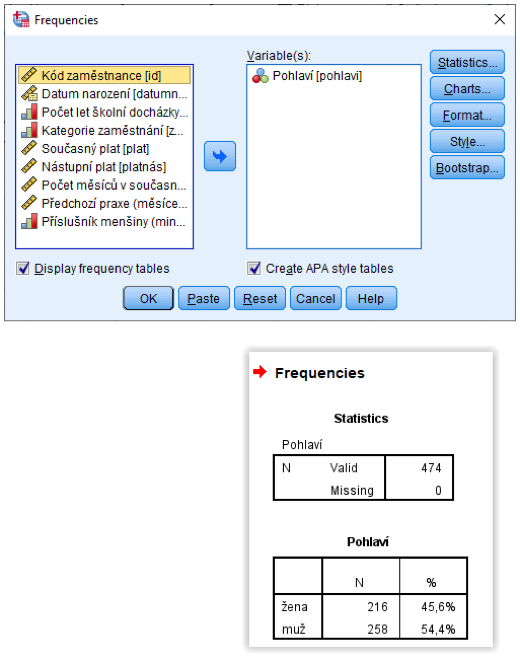
Procedury Frequencies a Crosstabs v nabídce Analyze, Descriptive Statistics nově nabízejí možnost zobrazit výstupní tabulku ve formátu, jaký vyžaduje American Psychological Association (APA). V dialogovém okně procedury Frequencies je k dispozici zaškrtávací políčko Create APA style tables, v dialogu procedury Crosstabs je třeba pod tlačítkem Cells zaškrtnout políčko Create APA style table.
Při zobrazení korelační matice pomocí nabídky Analyze, Correlate, Bivariate je nově možné zobrazit pouze dolní trojúhelník matice s diagonálou nebo bez diagonály. K tomuto účelu slouží zaškrtávací políčka Show only the lower triangle a Show diagonal.
Další novinky se týkají práce s grafy. V nabídce Edit, Options byla vylepšena záložka Charts, kde se nyní zobrazuje náhled šablony grafu a další detaily. Interaktivní rozhraní pro vytváření grafů Chart Builder (nabídka Graphs, Chart Builder) nabízí vylepšenou záložku Chart Appearance. Mezi další změny patří například možnost zadávat u bodových grafů nejen proměnnou určující barvu symbolů, ale také jejich velikost.
Ostatní
IBM SPSS Statistics ve verzi 27 nabízí možnost obnovení dat v případě, že byl program neočekávaně ukončen. Na spodní liště programu se nachází zelená ikona s disketou (Auto recovery), při poklikání na ni přepínáme mezi povolením/zákazem této funkcionality.

Na panelu nástrojů se nově nachází ikonka s modrou lupou (Search), která je určena pro rychlé vyhledávání v dokumentaci.

Verze Statistics 27 spolupracuje s Python 3.8.2. Rozšiřující procedury, které využívají Python, byly aktualizovány pro tuto verzi. Python 2 již není defaultně instalován. Uživatelé, kteří chtějí spouštět starší kód musí specifikovat cestu, kde je Python 2 nainstalován.
V nabídce Edit, Options je nově k dispozici záložka Privacy, která umožňuje nastavit soukromí.
Rádi byste se o statistice a analýze dat dozvěděli více? Chcete se stát mistrem ve svém oboru nebo si jen potřebujete doplnit znalosti? V ACREA nabízíme širokou nabídku kurzů pro váš profesní růst. Máte-li jiný dotaz. Nebojte se využít naši nezávaznou konzultaci, při které vám rádi zodpovíme všechny vaše dotazy a najdeme vhodné řešení.
